
大数据入门01-Hadoop运行环境搭建
这篇文章主要介绍的是Hadoop运行环境搭建
虚拟机环境准备
克隆虚拟机
修改克隆虚拟机的静态IP
进入 /etc/sysconfig/network-scripts中1
2cd /etc/sysconfig/network-scripts
vim ifcfg-eth0
需要对这几项进行修改: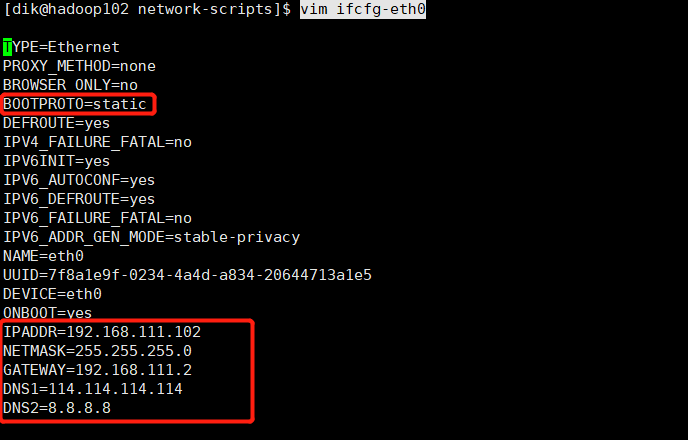
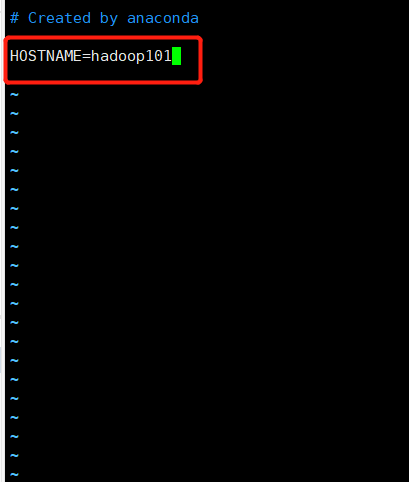
修改主机名
1 | cd /etc/sysconfig |
配置hosts文件
- 打开hosts文件
1
cd /etc/hosts
- 配置
1
2
3
4
5
6
7192.168.111.100 hadoop100
192.168.111.101 hadoop101
192.168.111.102 hadoop102
192.168.111.103 hadoop103
192.168.111.104 hadoop104
192.168.111.105 hadoop105
192.168.111.106 hadoop106
关闭防火墙
1 | systemctl stop firewalld.service |
禁止防火墙开机启动1
systemctl disable firewalld.service
在/opt目录下创建文件夹
在/opt目录下创建module、software文件夹,其中software文件夹用于软件包的存储,module文件夹用于软件的安装
1
2sudo mkdir module
sudo mkdir software修改module、software文件夹的所有者
1
sudo chown dik:dik module/ software/
安装JDK以及配置环境变量
卸载现有JDK
- 查询是否安装Java软件:
1
rpm -qa | grep java
- 用Xshell工具将JDK导入到opt目录下面的software文件夹下面
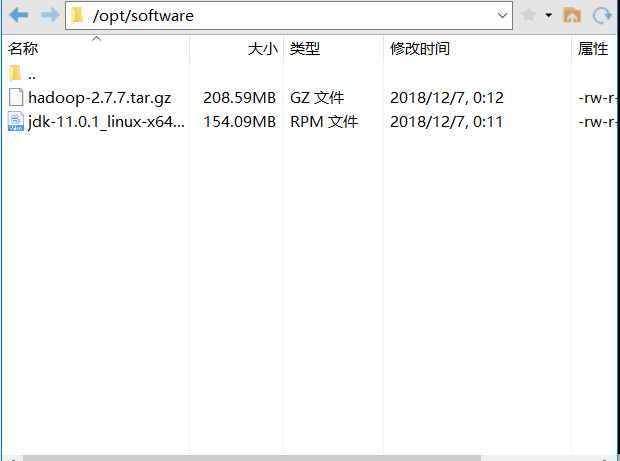
- 在Linux系统下的opt目录中查看软件包是否导入成功
解压JDK到/opt/module目录下
1 | tar -zxvf jdk-11.0.1_linux-x64_bin.tar.gz -C /opt/module/ |
配置JDK环境变量
- 先获取JDK路径
1
2[dik@hadoop102 jdk-11.0.1]$ pwd
/opt/module/jdk-11.0.1 - 打开/etc/profile文件
1
sudo vim /etc/profile
- 在profile文件末尾添加JDK路径
1
2export JAVA_HOME=/opt/module/jdk-11.0.1
export PATH=$PATH:$JAVA_HOME/bin
- 让修改后的文件生效
1
source /etc/profile
- 测试JDK是否安装成功

安装Hadoop以及配置环境变量
Hadoop下载地址:
https://archive.apache.org/dist/hadoop/common/hadoop-2.7.7/
也可以在官网直接下载。
导入Hadoop软件包
用Xshell工具将hadoop-2.7.7.tar.gz导入到opt目录下面的software文件夹下面
安装Hadoop
- 进入到Hadoop安装包路径下
1
cd /opt/software/
- 解压安装文件到/opt/module下面
1
tar -zxvf hadoop-2.7.7.tar.gz -C /opt/module/
将Hadoop添加到环境变量
- 获取Hadoop安装路径
1
2
3[dik@hadoop102 module]$ cd hadoop-2.7.7/
[dik@hadoop102 hadoop-2.7.7]$ pwd
/opt/module/hadoop-2.7.7 - 打开/etc/profile文件,在profile文件末尾添加hadoop路径
1
2
3
4##HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-2.7.7
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin - 让修改后的文件生效
1
source /etc/profile
- 测试是否安装成功
1
2
3
4
5
6
7[dik@hadoop102 hadoop-2.7.7]$ hadoop version
Hadoop 2.7.7
Subversion Unknown -r c1aad84bd27cd79c3d1a7dd58202a8c3ee1ed3ac
Compiled by stevel on 2018-07-18T22:47Z
Compiled with protoc 2.5.0
From source with checksum 792e15d20b12c74bd6f19a1fb886490
This command was run using /opt/module/hadoop-2.7.7/share/hadoop/common/hadoop-common-2.7.7.jarHadoop目录结构
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16[dik@hadoop102 hadoop-2.7.7]$ ll
total 116
drwxr-xr-x. 2 dik dik 194 Dec 6 23:56 bin
drwxrwxr-x. 3 dik dik 17 Dec 7 22:50 data
drwxr-xr-x. 3 dik dik 20 Dec 6 23:56 etc
drwxr-xr-x. 2 dik dik 106 Dec 6 23:56 include
drwxrwxr-x. 2 dik dik 187 Dec 6 23:58 input
drwxr-xr-x. 3 dik dik 20 Dec 6 23:56 lib
drwxr-xr-x. 2 dik dik 239 Dec 6 23:56 libexec
-rw-r--r--. 1 dik dik 86424 Dec 6 23:56 LICENSE.txt
drwxrwxr-x. 3 dik dik 4096 Dec 9 09:40 logs
-rw-r--r--. 1 dik dik 14978 Dec 6 23:56 NOTICE.txt
drwxrwxr-x. 2 dik dik 88 Dec 6 23:58 output
-rw-r--r--. 1 dik dik 1366 Dec 6 23:56 README.txt
drwxr-xr-x. 2 dik dik 4096 Dec 8 00:37 sbin
drwxr-xr-x. 4 dik dik 31 Dec 6 23:57 share重要目录
(1)bin目录:存放对Hadoop相关服务(HDFS,YARN)进行操作的脚本
(2)etc目录:Hadoop的配置文件目录,存放Hadoop的配置文件
(3)lib目录:存放Hadoop的本地库(对数据进行压缩解压缩功能)
(4)sbin目录:存放启动或停止Hadoop相关服务的脚本
(5)share目录:存放Hadoop的依赖jar包、文档、和官方案例
本地模式运行Hadoop
官方Grep案例
- 创建在hadoop-2.7.7文件下面创建一个input文件夹
1
mkdir input
- 将Hadoop的xml配置文件复制到input
1
cp etc/hadoop/*.xml input
- 执行share目录下的MapReduce程序
1
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar grep input output 'dfs[a-z.]+'
- 查看输出结果
1
cat output/*

到这里一个简单的Hadoop运行环境就搭建成功了!
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 我的技术小站!
相关推荐



评论




