
大数据入门04-pyspark环境搭建
安装Spark依赖的Scala
Hadoop的安装请参考上面提到的博文,因为Spark依赖scala,所以在安装Spark之前,这里要先安装scala。在每个节点上都进行安装。
下载和解压缩Scala
打开地址:https://www.scala-lang.org/download/
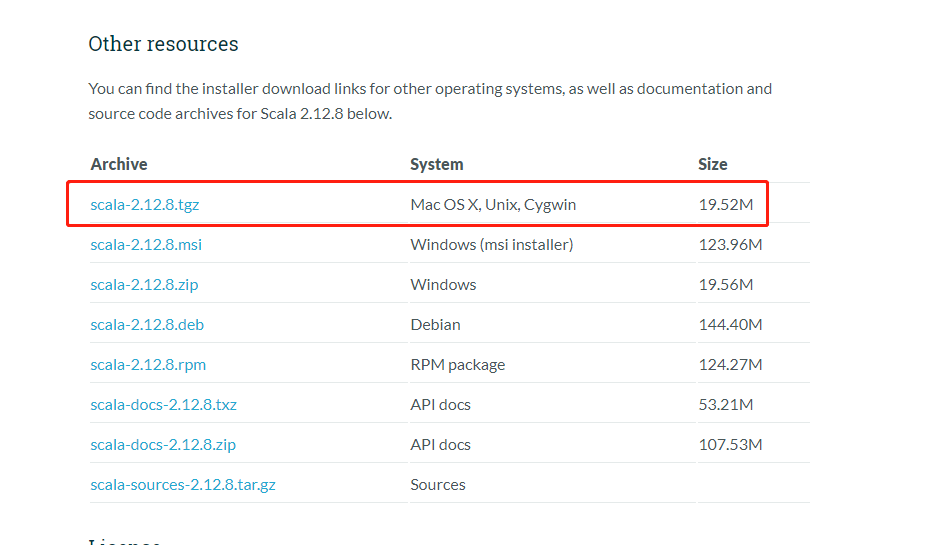
配置scala环境变量
- 打开配置文件
1
vim /etc/profile
1
2export SCALA_HOME=/root/module/scala-2.12.8
export PATH=$PATH:$SCALA_HOME/bin - 保存之后刷新配置文件
1
source /etc/profile
- 验证是否配置好
1
scala -version

下载和解压缩Spark
打开下载地址:
http://spark.apache.org/downloads.html
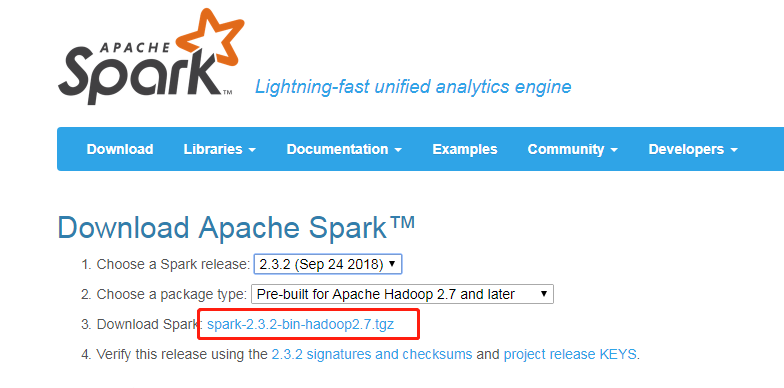
选择清华源
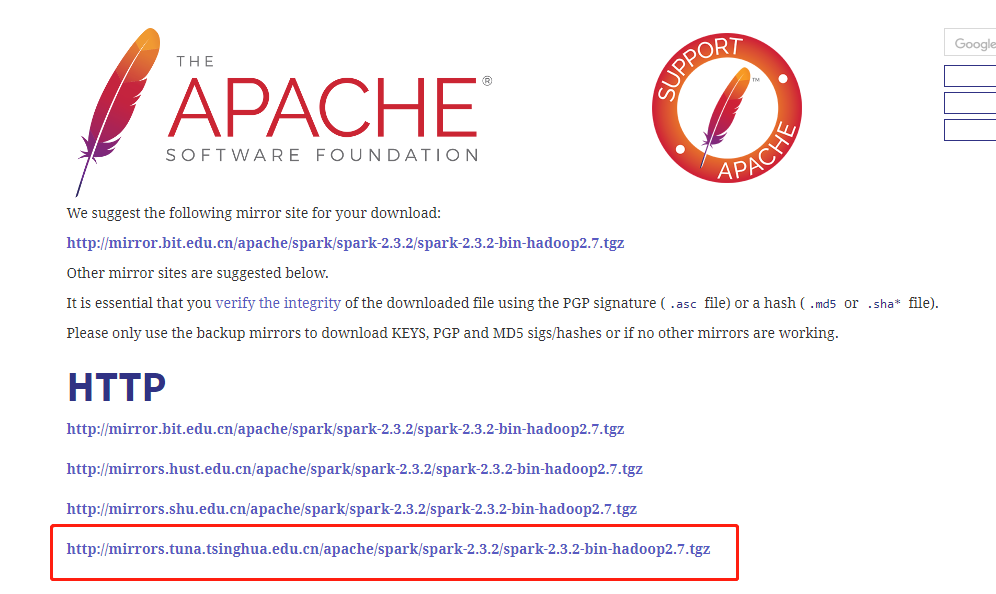
配置spark环境变量
- 编辑/etc/profile文件,添加
1 | export SPARK_HOME=/root/module/spark-2.3.2-bin-hadoop2.7 |
配置conf目录下的文件
/root/module/spark-2.3.2-bin-hadoop2.7/conf目录下的文件进行配置
新建spark-env.h文件
以spark为我们创建好的模板创建一个spark-env.h文件,命令是:1
cp spark-env.sh.template spark-env.sh
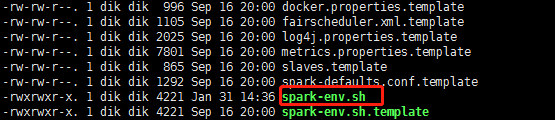
编辑spark-env.h文件,在里面加入配置(具体路径以自己的为准):
1 | export SCALA_HOME=/root/module/scala-2.12.8 |
新建slaves文件
/root/module/spark-2.3.2-bin-hadoop2.7/conf目录下的文件进行配置
以spark为我们创建好的模板创建一个slaves文件,命令是:1
cp slaves.template slaves
编辑slaves文件,里面的内容为:1
spark001
启动和测试Spark集群
启动Spark
- 切换到sbin目录
1
cd /root/module/spark-2.3.2-bin-hadoop2.7/sbin
- 执行启动脚本:
1
./start-all.sh

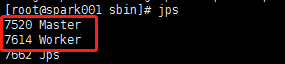
- 查看是否启动
1
jps
测试和使用Spark集群
访问Spark集群提供的URL
http://spark001:8080/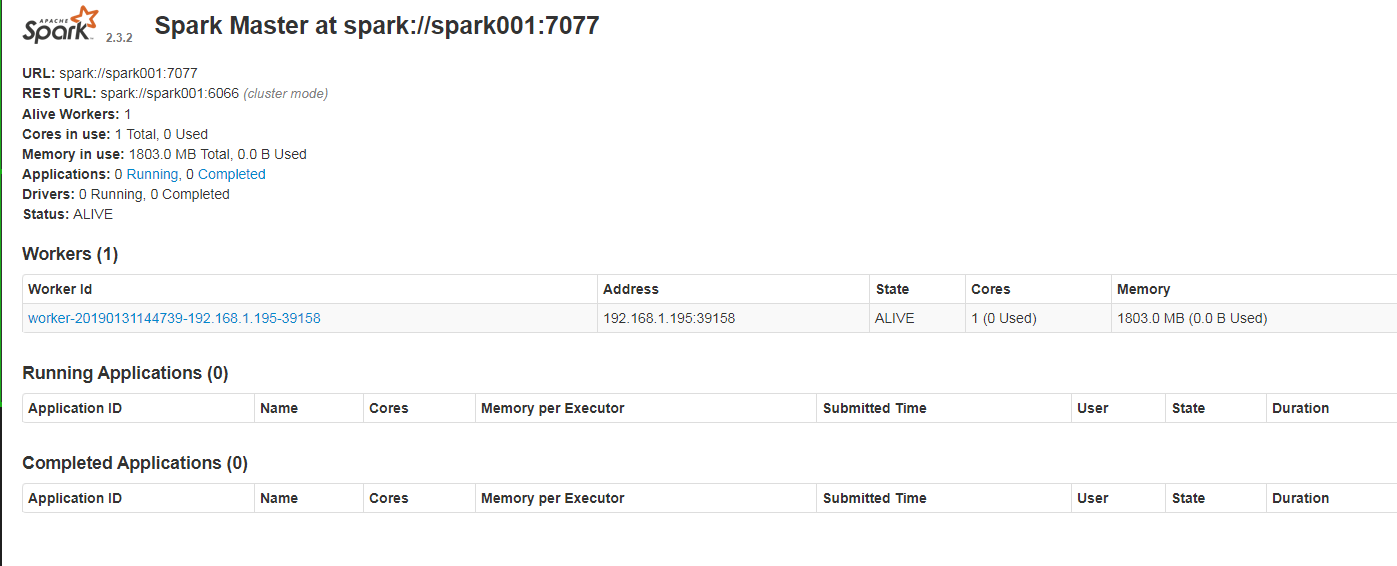
运行Spark提供的计算圆周率的示例程序
进入到Spark的根目录1
cd ..
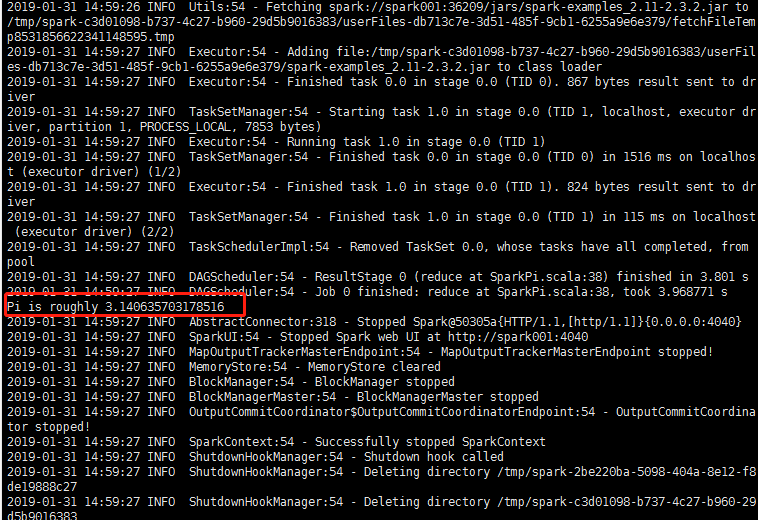
调用Spark自带的计算圆周率的Demo,执行下面的命令:
1 | ./bin/spark-submit --class org.apache.spark.examples.SparkPi --master local examples/jars/spark-examples_2.11-2.3.2.jar |
配置pyspark远程调试环境
安装Anaconda3
因为服务器自带的python版本是python2的,所以要安装python3,而Anaconda3是一个比较好的选择。
下载地址:
https://repo.continuum.io/archive/Anaconda3-5.1.0-Linux-x86_64.sh依赖安装bzip2: yum -y install bzip2
- 安装anaconda3安装的过程比较简单,这里就不复述了。
1
bash Anaconda3-5.0.1-Linux-x86_64.sh
安装完成之后刷新配置文件1
source ~/.bashrc
配置本地pycharm环境
- 安装py4j
1 | pip install py4j |
- 配置pycharm 远程
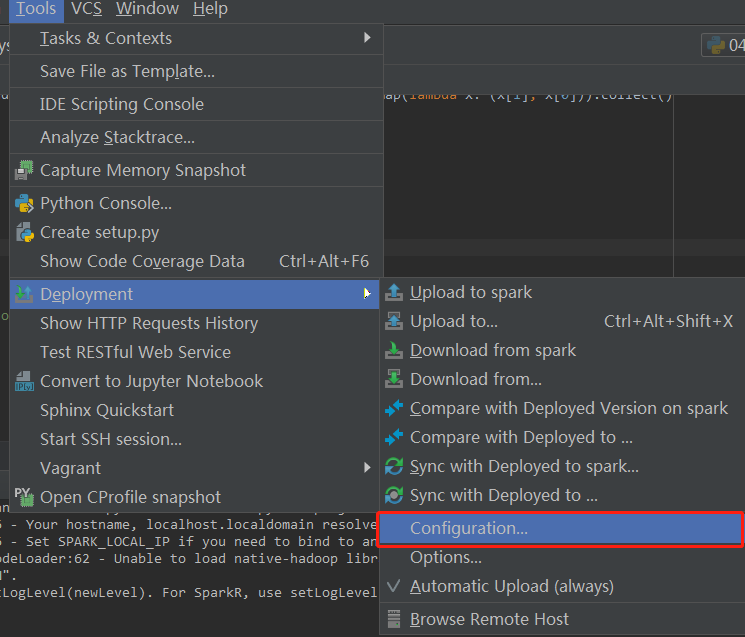
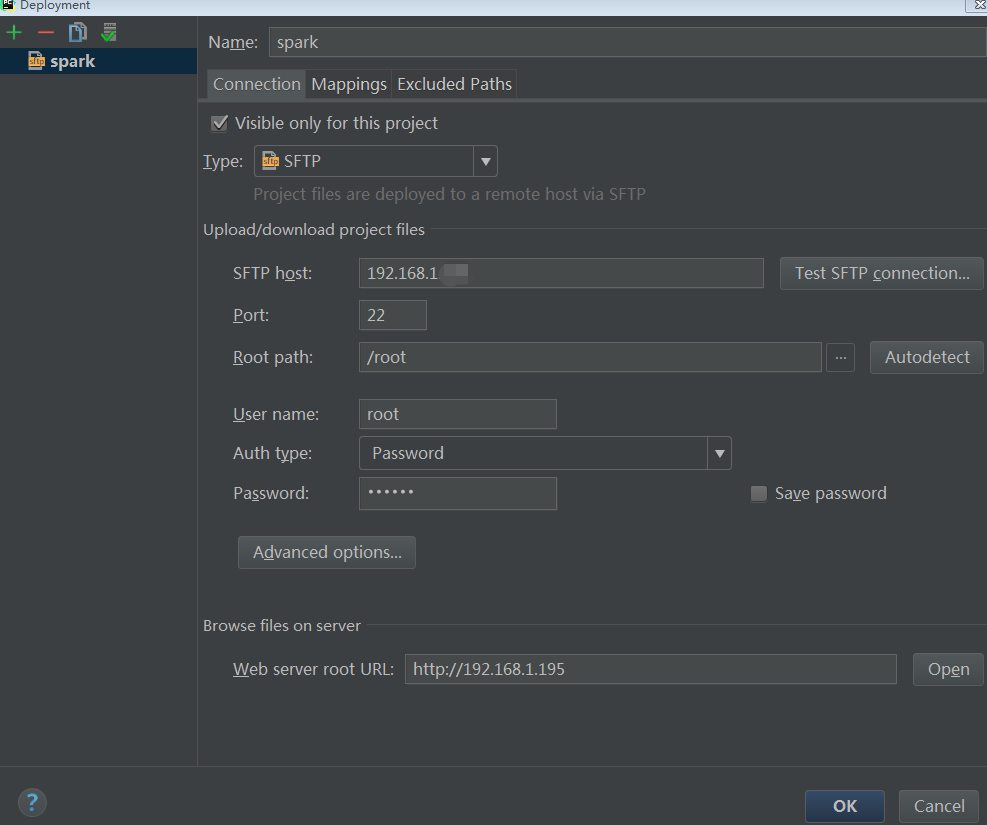
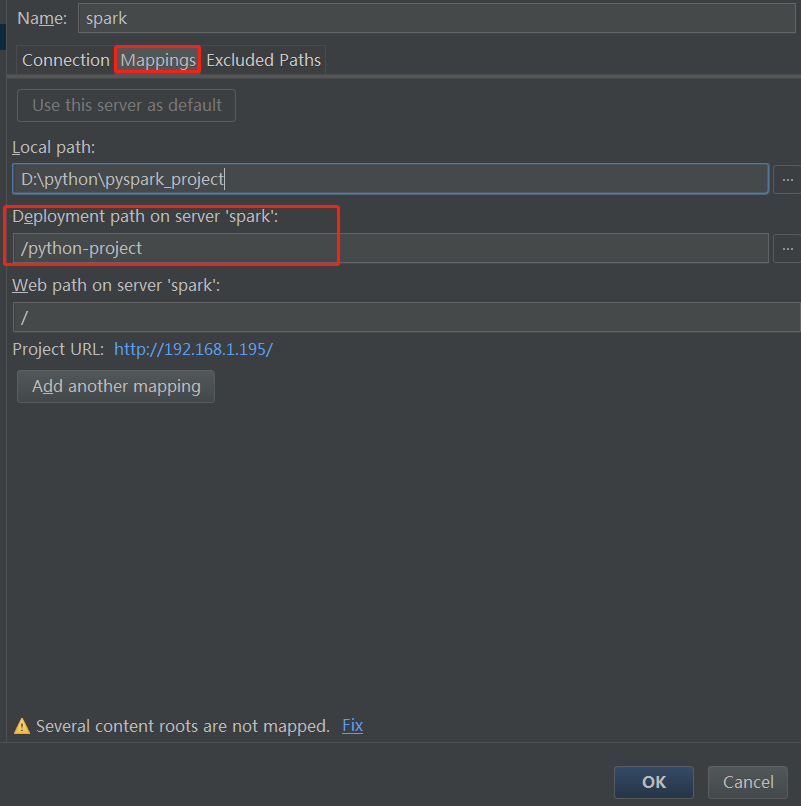
- 配置远程的编译器
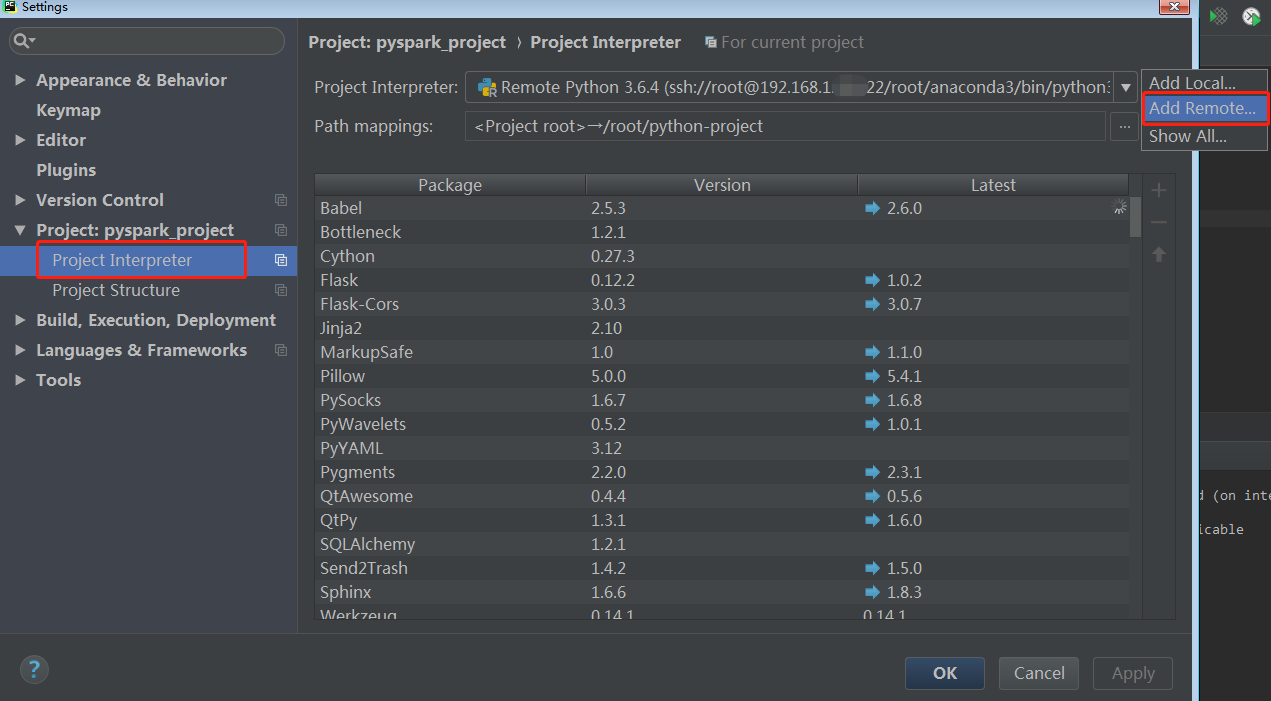
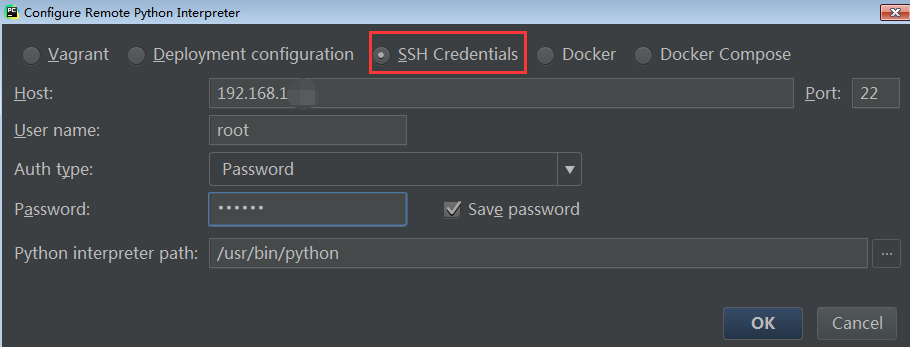
- 新建一个pyspark项目
填入以下测试代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24# -*- coding: UTF-8 -*-
from pyspark import SparkConf, SparkContext
def my_map():
"""
map(func)
将func函数作用到数据集的每一个元素上,生成一个新的分布式的数据集返回
word => (word,1)
:return:
"""
data = [1, 2, 3, 4, 5]
rdd1 = sc.parallelize(data)
rdd2 = rdd1.map(lambda x: x * 2)
print(rdd2.collect())
if __name__ == '__main__':
conf = SparkConf().setAppName('local[2]')
sc = SparkContext(conf=conf)
my_map()
sc.stop() - 配置
在里面加入对应的JAVA_HOME,PYTHONPATH,SPARK_HOME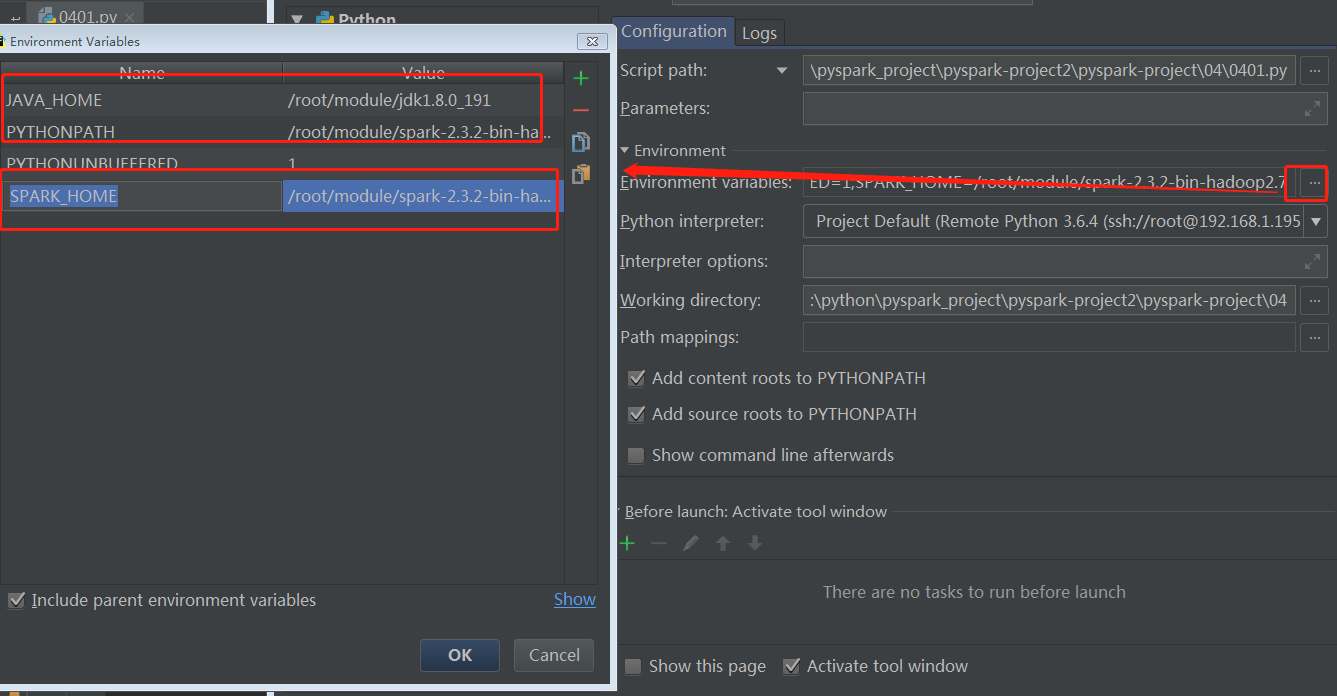
- 运行代码

如果没报错的话,那么就搭建成功了!
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 我的技术小站!
相关推荐



评论




