大数据入门03-Hadoop完全分布式运行模式
虚拟机准备
修改克隆主机的IP地址以及名字
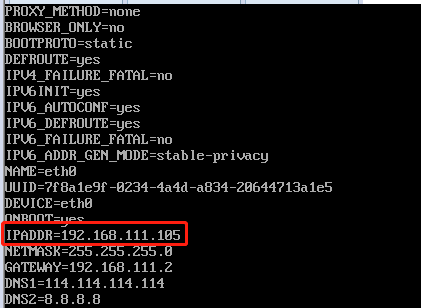
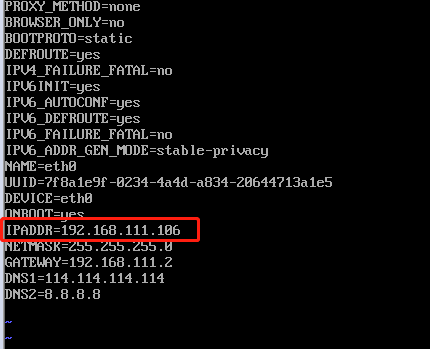
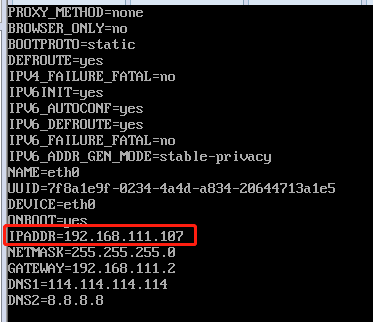
我们打开克隆的3台centos7虚拟机,修改里面对应的IP地址为105,106,107
1
vim /etc/sysconfig/network-scripts/ifcfg-eth0
修改MAC地址
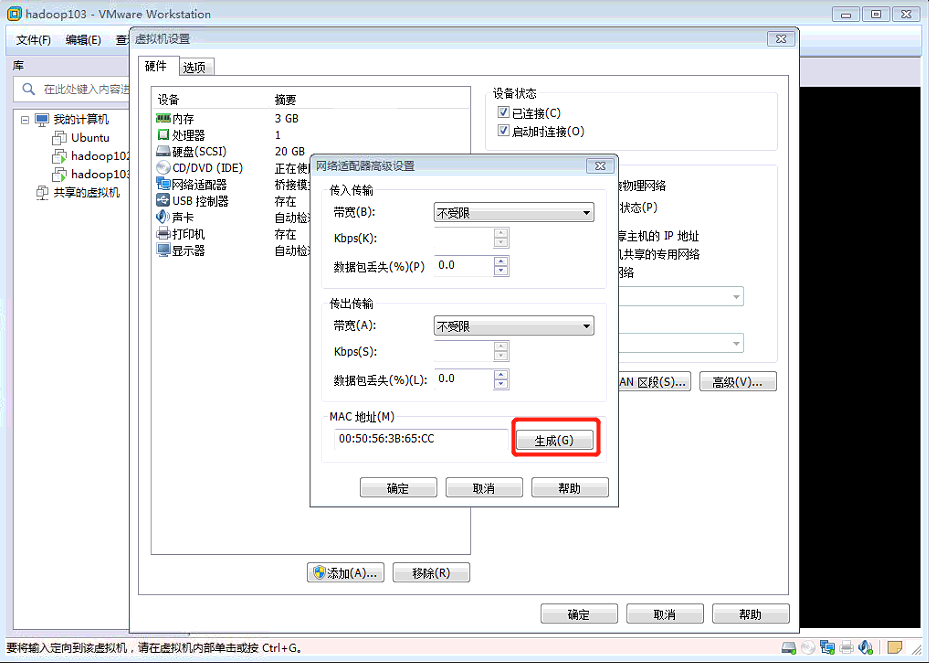
在配置IP地址的文件中添加:1
MACADDR=XXXXXXXXXXXXXXXX
修改主机的名字,分别为105,106,107
1
vim /etc/sysconfig/network
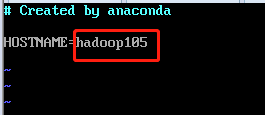
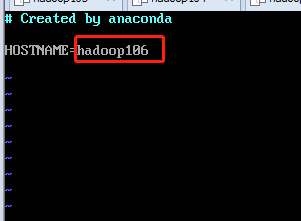
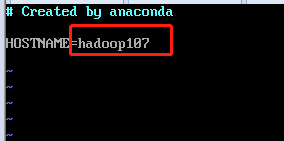
修改hosts配置文件,添加对应的105,106,107的IP地址
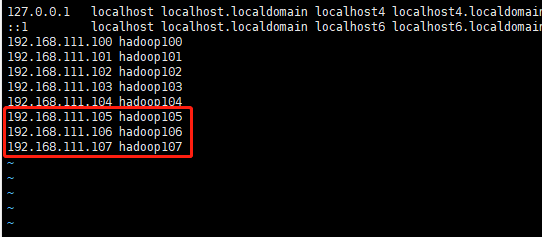
为三台虚拟机配置ssh
分别在105,106,107上面创建ssh1
ssh-keygen -t rsa
然后敲(三个回车),就会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
进入到.ssh文件夹,将产生的公钥拷贝到目标机器上1
2
3ssh-copy-id hadoop105
ssh-copy-id hadoop106
ssh-copy-id hadoop107编写xsync集群分发脚本
在~/bin目录在创建xsync创建文件,文件内容如下:1
2touch xsync
vim xsync1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26#!/bin/bash
#1 获取输入参数个数,如果没有参数,直接退出
pcount=$#
if((pcount==0)); then
echo no args;
exit;
fi
#2 获取文件名称
p1=$1
fname=`basename $p1`
echo fname=$fname
#3 获取上级目录到绝对路径
pdir=`cd -P $(dirname $p1); pwd`
echo pdir=$pdir
#4 获取当前用户名称
user=`whoami`
#5 循环
for((host=103; host<105; host++)); do
echo ------------------- hadoop$host --------------
rsync -rvl $pdir/$fname $user@hadoop$host:$pdir
done其中#5 循环部分可以改成对应的主机名称
修改脚本 xsync 具有执行权限1
chmod 777 xsync
集群配置

核心配置文件
配置core-site.xml1
2[root@hadoop105 ~]# cd /opt/module/hadoop-2.7.7/etc/hadoop/
[root@hadoop105 hadoop]# vim core-site.xml把namenode节点改成105
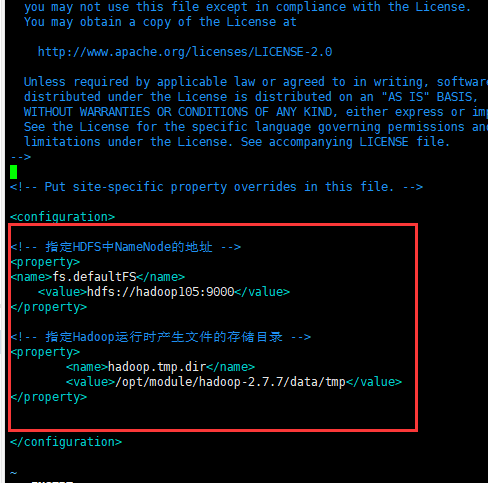
- HDFS配置文件
配置hadoop-env.sh
1 | [root@hadoop105 hadoop]# vim hadoop-env.sh |
配置hdfs-site.xml1
[root@hadoop105 hadoop]# vim hdfs-site.xml
在该文件中编写如下配置1
2
3
4
5<!-- 指定Hadoop辅助名称节点主机配置 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop107:50090</value>
</property>
- YARN配置文件
配置yarn-env.sh1
2[root@hadoop105 hadoop]# vim yarn-env.sh
export JAVA_HOME=/opt/module/jdk-11.0.1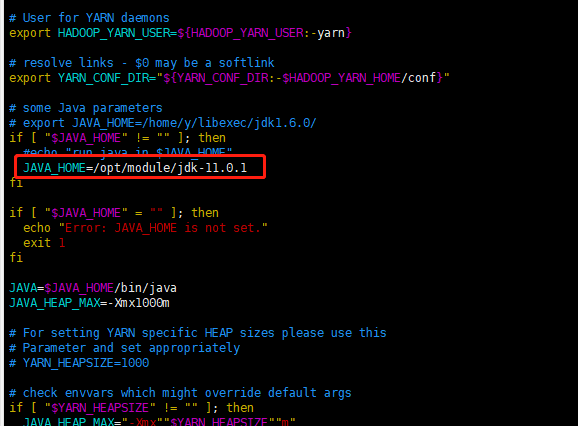
配置yarn-site.xml1
2
3
4
5
6
7
8
9
10
11
12<!-- Reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop106</value>
</property> - MapReduce配置文件
配置mapred-env.sh配置mapred-site.xml1
2[root@hadoop105 hadoop]# vim mapred-env.sh
export JAVA_HOME=/opt/module/jdk-11.0.1接着用xsync脚本把编写的文件同步到106,1071
2
3
4
5
6
7
8
9[root@hadoop105 hadoop]# cp mapred-site.xml.template mapred-site.xml
[root@hadoop105 hadoop]# vim mapred-site.xml
<!-- 指定MR运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>1
xsync /opt/module/hadoop-2.7.7/etc/hadoop/
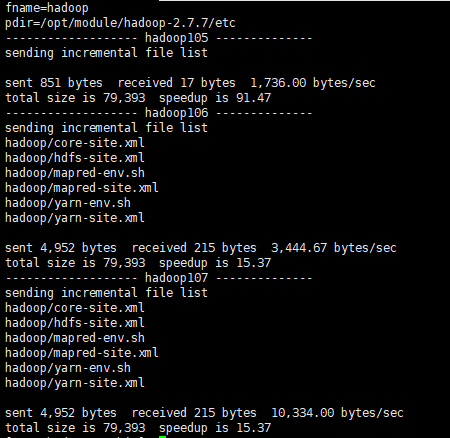
群起集群
- 格式化NameNode
格式化之前,一定要先停止上次启动的所有namenode和datanode进程,然后再分别在105,106,107上删除data和log数据1
2rm -rf data/ logs/
bin/hdfs namenode -format 配置slaves
1
2
3
4[root@hadoop105 hadoop-2.7.7]# vim etc/hadoop/slaves
hadoop105
hadoop106
hadoop107接着把它分发到106,107
1
~/bin/xsync /opt/module/hadoop-2.7.7/etc/hadoop/slaves
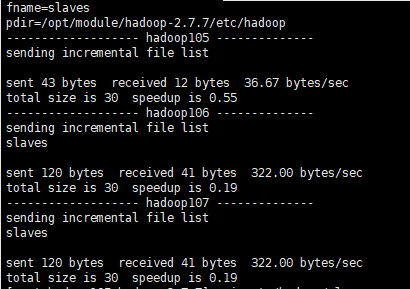
启动HDFS
在hadoop105上启动:1
2sbin/start-dfs.sh
#sbin/stop-dfs.sh (关闭)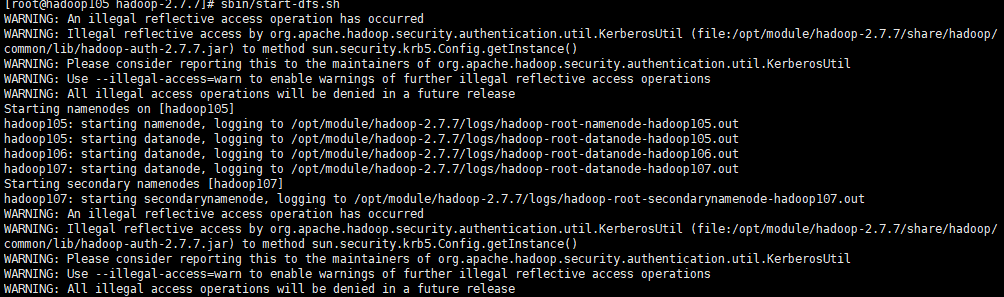
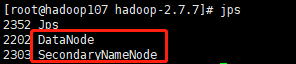
分别在105,106,107上面用jps命令查看是否启动正确: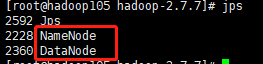

启动YARN
在hadoop106上启动:1
2sbin/start-yarn.sh
#sbin/stop-yarn.sh (关闭)
启动之后再在105,106,107上面用jps命令查看是否启动正确: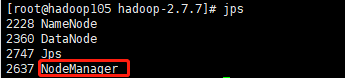
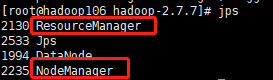
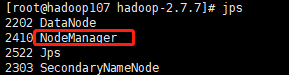
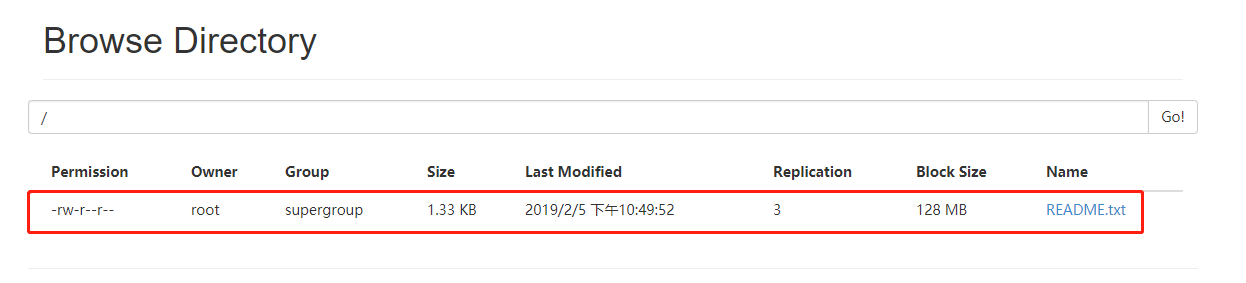
最后我们登录 http://hadoop105:50070/explorer.html#/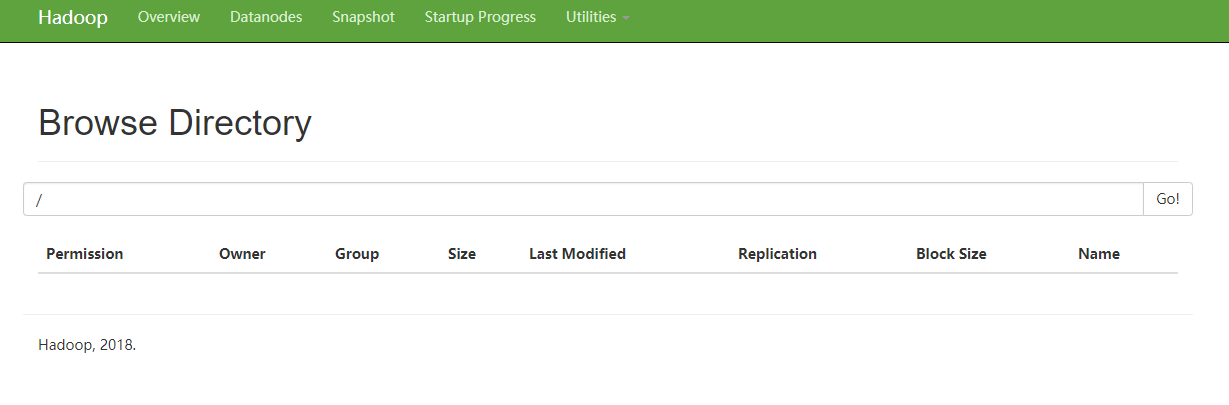
如果能成功打开,那么我们完全分布式集群就搭建成功了!
集群基本测试
我们上传一个小文件到集群上面用作测试:1
bin/hdfs dfs -put README.txt /