
大数据入门05-spark运行模式
本地模式
本地模式是我们在IDE上面编写完程序,然后运行的一种模式。1
2
3
4
5
6
7
8./bin/spark-submit \
--class <main-class> \
--master <master-url> \
--deploy-mode <deploy-mode> \
--conf <key>=<value> \
... # other options
<application-jar> \
[application-arguments]
常用的 options :
- —class: 您的应用程序的入口点(例如。 org.apache.spark.examples.SparkPi)
- —master: 集群的 master URL (例如 spark://23.195.26.187:7077)
- —deploy-mode: 是在 worker 节点(cluster) 上还是在本地作为一个外部的客户端(client) 部署您的 driver(默认: client) †
- —conf: 按照 key=value 格式任意的 Spark 配置属性。对于包含空格的 value(值)使用引号包 “key=value” 起来。
- application-jar: 包括您的应用以及所有依赖的一个打包的 Jar 的路径。该 URL 在您的集群上必须是全局可见的,例如,一个 hdfs:// path 或者一个 file:// 在所有节点是可见的。(对于 Python 应用,在 <application-jar> 的位置简单的传递一个 .py 文件而不是一个 JAR,并且可以用 —py-files 添加 Python .zip,.egg 或者 .py 文件到 search path(搜索路径))
- application-arguments: 传递到您的 main class 的 main 方法的参数,如果有的话。
简单例子
1 | ./spark-submit --master local[2] --name spark-local /home/dik/python-project/03/spark0301.py |
Spark on yarn模式
spark on yarn模式是我们工作中用的比较多的一种模式,其用法其实跟本地模式是比较类似的。spark作为客户端而已,他需要做的事情就是提交作业到yarn上去执行
配置spark on yarn
- 配置HADOOP_CONF_DIR 或者 YARN_CONF_DIR
1 | vim /spark-2.3.2-bin-hadoop2.7/conf/spark-env.sh |
添加1
HADOOP_CONF_DIR=/opt/module/hadoop-2.7.7/etc/hadoop
简单例子
1 | ./spark-submit --master yarn --name spark-local /home/dik/python-project/03/spark0301.py |
deploy mode
yarn支持client和cluster模式:driver运行在哪里
- client:提交作业的进程是不能停止的,否则作业就挂了
- cluster:提交完作业,那么提交作业端就可以断开了,因为driver是运行在am里面的
开启历史日志监控
spark的作业如果正在运行的话,我们可以在4040端口上面看,但是如果作业结束的话,我们便无法查看了。因此我们需要建立一个历史日志监控的系统。
- 在/spark-2.3.2-bin-hadoop2.7/conf目录中创建spark-defaults.conf文件
1
cp spark-defaults.conf.template spark-defaults.conf
在当前安装Spark的节点上,进入到conf目录,在配置文件spark-defaults.conf添加下面的配置
1
2spark.eventLog.enabled true # 开启日志记录
spark.eventLog.dir hdfs://hadoop101:9000/directory # 日志的保存位置配置spark-env.sh 文件
添加1
SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://hadoop101:9000/directory"
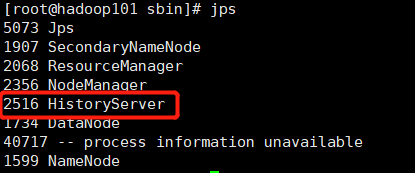
- 在/sbin目录下启动历史日志
1
./start-history-server.sh

本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 我的技术小站!
相关推荐



评论




