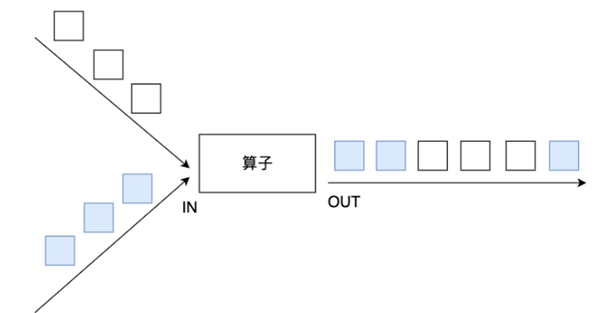
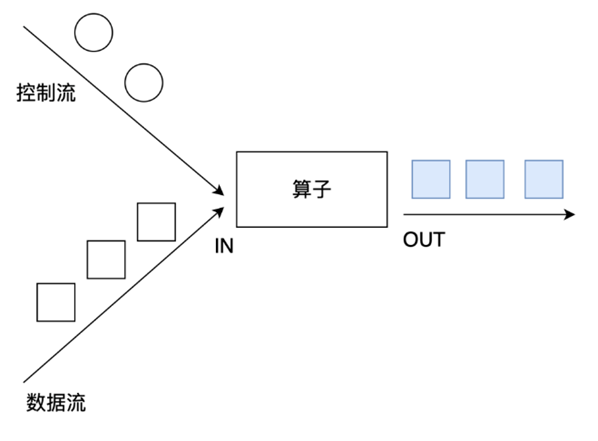
流处理相关概念 数据的时效性 日常工作中,我们一般会先把数据存储在表,然后对表的数据进行加工、分析。既然先存储在表中,那就会涉及到时效性概念。
如果我们处理以年,月为单位的级别的数据处理,进行统计分析,个性化推荐,那么数据的的最新日期离当前有几个甚至上月都没有问题。但是如果我们处理的是以天为级别,或者一小时甚至更小粒度的数据处理,那么就要求数据的时效性更高了。比如:对网站的实时监控、对异常日志的监控,这些场景需要工作人员立即响应,这样的场景下,传统的统一收集数据,再存到数据库中,再取出来进行分析就无法满足高时效性的需求了。
流处理和批处理 官方介绍:https://ci.apache.org/projects/flink/flink-docs-release-1.12/zh/learn-flink/
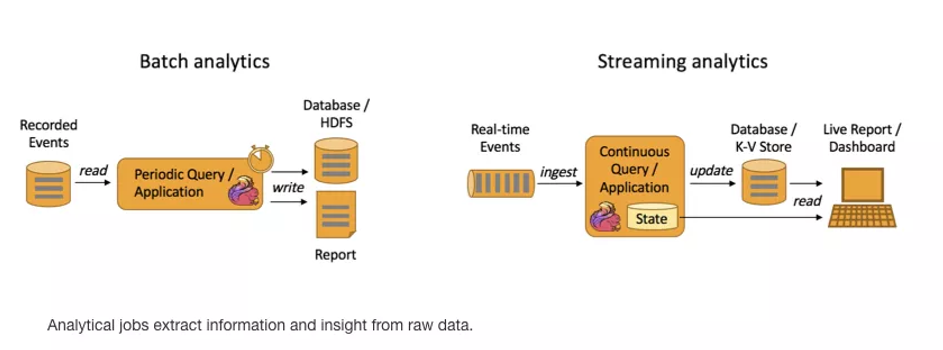
Batch Analytics,右边是 Streaming Analytics。批量计算: 统一收集数据->存储到DB->对数据进行批量处理,就是传统意义上使用类似于 Map Reduce、Hive、Spark Batch 等,对作业进行分析、处理、生成离线报表
Streaming Analytics 流式计算,顾名思义,就是对数据流进行处理,如使用流式分析引擎如 Storm,Flink 实时处理分析数据,应用较多的场景如实时大屏、实时报表。
流计算与批计算对比
数据时效性不同:
数据特性不同:
流式计算的数据一般是动态的、没有边界的,而批处理的数据一般则是静态数据。
应用场景不同:
流式计算应用在实时场景,时效性要求比较高的场景,如实时推荐、业务监控。
批处理应用在实时性要求不高、离线计算的场景下,数据分析、离线报表等。
运行方式不同:
流式计算的任务持续进行
批量计算的任务则一次性完成
流批一体API DataStream API Flink 的核心 API 最初是针对特定的场景设计的,尽管 Table API / SQL 针对流处理和批处理已经实现了统一的 API,但当用户使用较底层的 API 时,仍然需要在批处理(DataSet API)和流处理(DataStream API)这两种不同的 API 之间进行选择。鉴于批处理是流处理的一种特例,将这两种 API 合并成统一的 API,有一些非常明显的好处,比如:
考虑到这些优点,社区已朝着流批统一的 DataStream API 迈出了第一步:支持高效的批处理(FLIP-134)。从长远来看,这意味着 DataSet API 将被弃用(FLIP-131),其功能将被包含在 DataStream API 和 Table API / SQL 中。
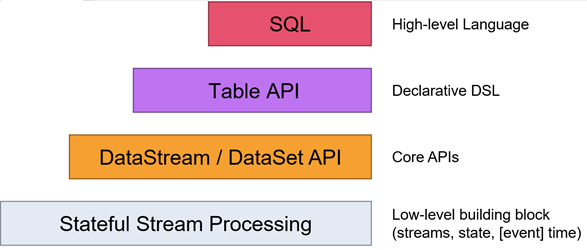
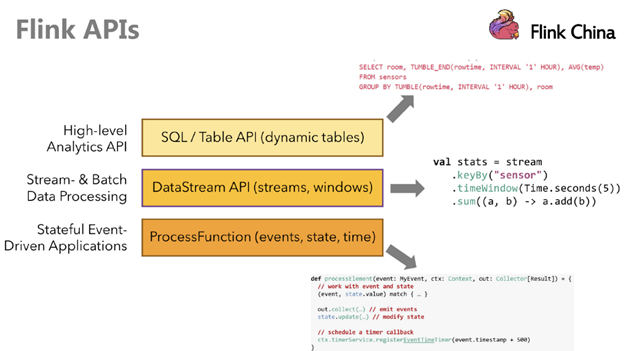
Flink API Flink提供了多个层次的API供开发者使用,越往上抽象程度越高,使用起来越方便;越往下越底层,使用起来难度越大
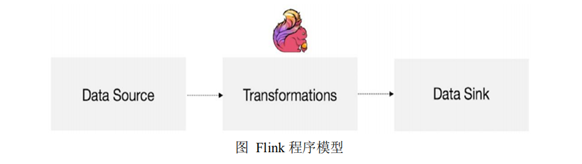
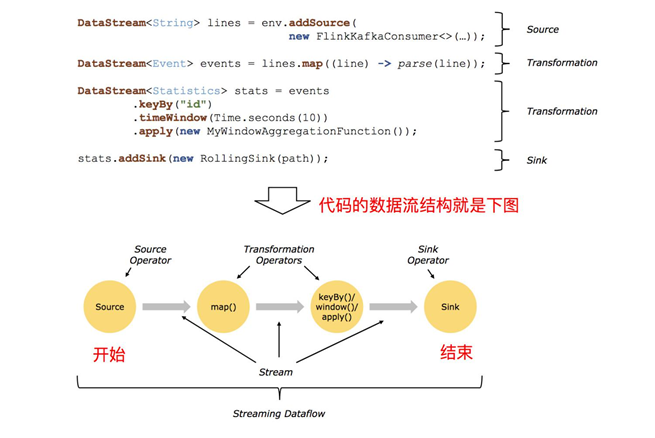
编程模型 Flink 应用程序结构主要包含三部分,Source/Transformation/Sink,如下图所示:
Source
预定义Source 基于集合的Source
API
env.fromElements(可变参数)
env.fromColletion(各种集合)
env.generateSequence(开始,结束)
env.fromSequence(开始,结束)
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 public class SourceDemo01 { public static void main (String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC); DataStream<String> ds1 = env.fromElements("itcast hadoop spark" , "itcast hadoop spark" , "itcast hadoop" , "itcast" ); DataStream<String> ds2 = env.fromCollection(Arrays.asList("itcast hadoop spark" , "itcast hadoop spark" , "itcast hadoop" , "itcast" )); DataStream<Long> ds3 = env.generateSequence(1 , 100 ); DataStream<Long> ds4 = env.fromSequence(1 , 100 ); ds1.print(); ds2.print(); ds3.print(); ds4.print(); env.execute(); } }
基于文件的Source
API
env.readTextFile(本地/HDFS文件/文件夹);//压缩文件也可以
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 public class SourceDemo02 { public static void main (String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC); DataStream<String> ds1 = env.readTextFile("data/input/words.txt" ); DataStream<String> ds2 = env.readTextFile("data/input/dir" ); DataStream<String> ds3 = env.readTextFile("hdfs://master:8020//wordcount/input/words.txt" ); DataStream<String> ds4 = env.readTextFile("data/input/wordcount.txt.gz" ); ds1.print(); ds2.print(); ds3.print(); ds4.print(); env.execute(); } }
基于Socket的Source
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 public class SourceDemo03 { public static void main (String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC); DataStream<String> linesDS = env.socketTextStream("node1" , 9999 ); DataStream<String> wordsDS = linesDS.flatMap(new FlatMapFunction <String, String>() { @Override public void flatMap (String value, Collector<String> out) throws Exception { String[] words = value.split(" " ); for (String word : words) { out.collect(word); } } }); DataStream<Tuple2<String, Integer>> wordAndOnesDS = wordsDS.map(new MapFunction <String, Tuple2<String, Integer>>() { @Override public Tuple2<String, Integer> map (String value) throws Exception { return Tuple2.of(value, 1 ); } }); KeyedStream<Tuple2<String, Integer>, String> groupedDS = wordAndOnesDS.keyBy(t -> t.f0); DataStream<Tuple2<String, Integer>> result = groupedDS.sum(1 ); result.print(); env.execute(); } }
自定义Source 随机生成数据
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 public class SourceDemo04 { public static void main (String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC); DataStream<Order> orderDs = env.addSource(new MyOrderSource ()).setParallelism(2 ); orderDs.print(); env.execute(); } @Data @AllArgsConstructor @NoArgsConstructor public static class Order { private String id; private Integer userId; private Integer money; private Long createTime; } public static class MyOrderSource extends RichParallelSourceFunction <Order>{ private Boolean flag = true ; @Override public void run (SourceContext<Order> ctx) throws Exception { Random random = new Random (); while (flag){ String oid = UUID.randomUUID().toString(); int userId = random.nextInt(3 ); int money = random.nextInt(101 ); long createTime = System.currentTimeMillis(); ctx.collect(new Order (oid,userId,money,createTime)); Thread.sleep(1000 ); } } @Override public void cancel () { flag = false ; } } }
MySQL 实际开发中,经常会实时接收一些数据,要和MySQL中存储的一些规则进行匹配,那么这时候就可以使用Flink自定义数据源从MySQL中读取数据
准备数据
1 2 3 4 5 6 7 8 9 10 11 12 13 CREATE TABLE `t_student` ( `id` int (11 ) NOT NULL AUTO_INCREMENT, `name` varchar (255 ) DEFAULT NULL , `age` int (11 ) DEFAULT NULL , PRIMARY KEY (`id`) ) ENGINE= InnoDB AUTO_INCREMENT= 7 DEFAULT CHARSET= utf8; INSERT INTO `t_student` VALUES ('1' , 'jack' , '18' );INSERT INTO `t_student` VALUES ('2' , 'tom' , '19' );INSERT INTO `t_student` VALUES ('3' , 'rose' , '20' );INSERT INTO `t_student` VALUES ('4' , 'tom' , '19' );INSERT INTO `t_student` VALUES ('5' , 'jack' , '18' );INSERT INTO `t_student` VALUES ('6' , 'rose' , '20' );
示例代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 public class SourceDemo05 { public static void main (String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC); DataStream<Student> studentDs = env.addSource(new MySQLSource ()).setParallelism(1 ); studentDs.print(); env.execute(); } public static class MySQLSource extends RichParallelSourceFunction <Student>{ private boolean flag = true ; private Connection conn = null ; private PreparedStatement ps = null ; private ResultSet rs = null ; @Override public void open (Configuration parameters) throws Exception { conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/example?useSSL=false" ,"root" ,"root" ); String sql = "select id , name ,age from t_student " ; ps = conn.prepareStatement(sql); } @Override public void run (SourceContext<Student> ctx) throws Exception { while (flag){ rs = ps.executeQuery(); while (rs.next()){ int id = rs.getInt("id" ); String name = rs.getString("name" ); int age = rs.getInt("age" ); ctx.collect(new Student (id,name,age)); } Thread.sleep(5000 ); } } @Override public void cancel () { flag = false ; } @Override public void close () throws Exception { if (conn != null ){ conn.close(); } if (ps != null ){ ps.close(); } if (rs != null ){ rs.close(); } } } }
官网API列表:https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/stream/operators/
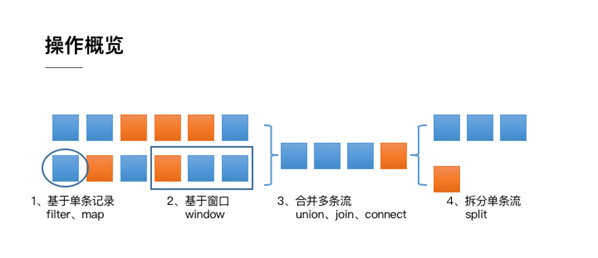
整体来说,流式数据上的操作可以分为四类:
第一类是对于单条记录的操作,比如筛除掉不符合要求的记录(Filter 操作),或者将每条记录都做一个转换(Map 操作)
第二类是对多条记录的操作。比如说统计一个小时内的订单总成交量,就需要将一个小时内的所有订单记录的成交量加到一起。为了支持这种类型的操作,就得通过 Window 将需要的记录关联到一起进行处理
第三类是对多个流进行操作并转换为单个流。例如,多个流可以通过 Union、Join 或Connect 等操作合到一起。这些操作合并的逻辑不同,但是它们最终都会产生了一个新的统一的流,从而可以进行一些跨流的操作。
第四类 DataStream 还支持与合并对称的拆分操作,即把一个流按一定规则拆分为多个流(Split操作),每个流是之前流的一个子集,这样我们就可以对不同的流作不同的处理。
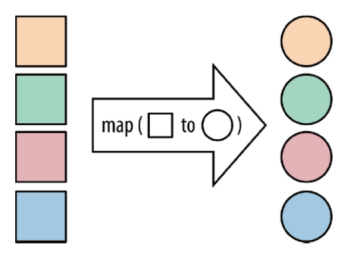
基本操作 map map:将函数作用在集合中的每一个元素上,并返回作用后的结果
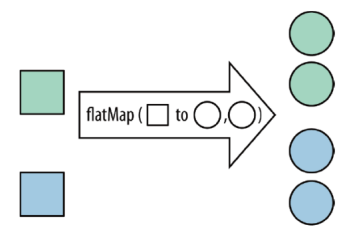
flatMap flatMap:将集合中的每个元素变成一个或多个元素,并返回扁平化之后的结果
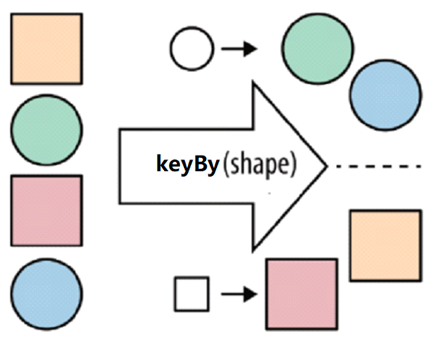
keyBy 按照指定的key来对流中的数据进行分组
注意: 流处理中没有groupBy,而是keyBy
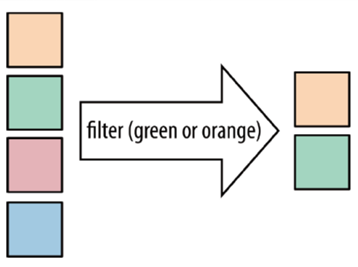
filter filter:按照指定的条件对集合中的元素进行过滤,过滤出返回true/符合条件的元素
sum sum:按照指定的字段对集合中的元素进行求和
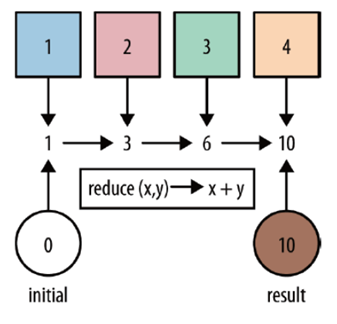
reduce reduce:对集合中的元素进行聚合
综合例子 对流数据中的单词进行统计,排除敏感词heihei
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 public class TransformationDemo01 { public static void main (String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC); DataStreamSource<String> lines = env.socketTextStream("localhost" , 9999 ); SingleOutputStreamOperator<String> words = lines.flatMap(new FlatMapFunction <String, String>() { @Override public void flatMap (String value, Collector<String> out) throws Exception { String[] arr = value.split(" " ); for (String word : arr) { out.collect(word); } } }); SingleOutputStreamOperator<String> filtered = words.filter(new FilterFunction <String>() { @Override public boolean filter (String value) throws Exception { return !value.equals("TMD" ); } }); SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOne = filtered.map(new MapFunction <String, Tuple2<String, Integer>>() { @Override public Tuple2 map (String s) throws Exception { return Tuple2.of(s, 1 ); } }); KeyedStream<Tuple2<String, Integer>, String> grouped = wordAndOne.keyBy(t -> t.f0); SingleOutputStreamOperator<Tuple2<String, Integer>> result = grouped.reduce(new ReduceFunction <Tuple2<String, Integer>>() { @Override public Tuple2<String, Integer> reduce (Tuple2<String, Integer> value1, Tuple2<String, Integer> value2) throws Exception { return Tuple2.of(value1.f0, value1.f1 + value2.f1); } }); result.print(); env.execute(); } }
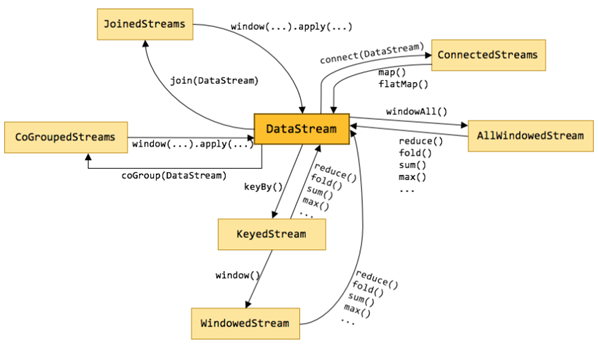
合并-拆分 union和connect
示例代码:
split、select和Side Outputs
示例代码:
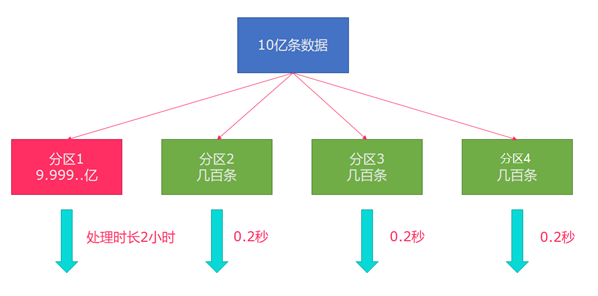
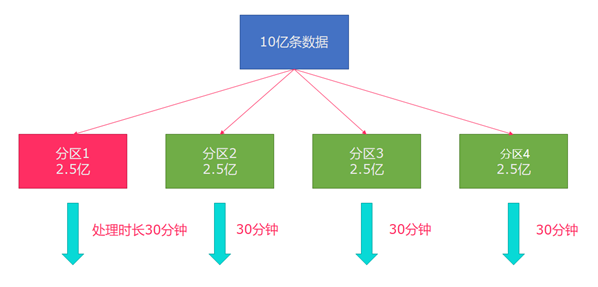
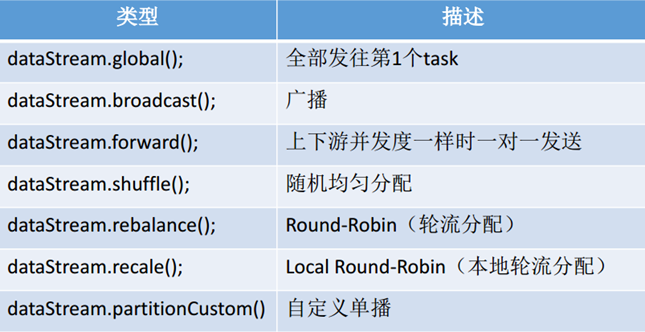
分区 rebalance重平衡分区 类似于Spark中的repartition,但是功能更强大,可以直接解决数据倾斜
Flink也有数据倾斜的时候,比如当前有数据量大概10亿条数据需要处理,在处理过程中可能会发生如图所示的状况,出现了数据倾斜,其他3台机器执行完毕也要等待机器1执行完毕后才算整体将任务完成
所以在实际的工作中,出现这种情况比较好的解决方案就是rebalance(内部使用round robin方法将数据均匀打散)
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 public class TransformationDemo04 { public static void main (String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC); DataStream<Long> longDS = env.fromSequence(0 , 100 ); DataStream<Long> filterDS = longDS.filter(new FilterFunction <Long>() { @Override public boolean filter (Long num) throws Exception { return num > 10 ; } }); SingleOutputStreamOperator<Tuple2<Integer, Integer>> result1 = filterDS.map(new RichMapFunction <Long, Tuple2<Integer, Integer>>() { @Override public Tuple2<Integer, Integer> map (Long aLong) throws Exception { int subtaskId = getRuntimeContext().getIndexOfThisSubtask(); return Tuple2.of(subtaskId, 1 ); } }).keyBy(t -> t.f0) .sum(1 ); SingleOutputStreamOperator<Tuple2<Integer, Integer>> result2 = filterDS.rebalance().map(new RichMapFunction <Long, Tuple2<Integer, Integer>>() { @Override public Tuple2<Integer, Integer> map (Long aLong) throws Exception { int subtaskId = getRuntimeContext().getIndexOfThisSubtask(); return Tuple2.of(subtaskId, 1 ); } }).keyBy(t -> t.f0) .sum(1 ); env.execute(); } }
其他分区
Sink
预定义Sink 基于控制台和文件的Sink
ds.print直接输出到控制台
ds.printToErr()直接输出到控制台,用红色
ds.writeAsText(“本地/HDFS的path”,WriteMode.OVERWRITE).setParallelism(1)
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 public class SinkDemo01 { public static void main (String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC); DataStream<String> ds = env.readTextFile("src/main/resources/words.txt" ); ds.print("输出标识" ); ds.printToErr(); ds.writeAsText("data/output/result1" ).setParallelism(1 ); ds.writeAsText("data/output/result2" ).setParallelism(2 ); env.execute(); } }
自定义Sink MySQL 将Flink集合中的数据通过自定义Sink保存到MySQL
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 public class SinkDemo02 { public static void main (String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC); DataStreamSource<Student> studentDs = env.fromElements(new Student (null , "tonyma" , 18 )); studentDs.addSink(new MySQLSink ()); env.execute(); } public static class MySQLSink extends RichSinkFunction <Student> { private Connection conn = null ; private PreparedStatement ps = null ; @Override public void open (Configuration parameters) throws Exception { conn = DriverManager.getConnection("jdbc:mysql://127.0.0.1:3306/db?useSSL=false" ,"root" ,"root" ); String sql = "insert into student(`id`,`name`,`age`) values (null ,?,?) " ; ps = conn.prepareStatement(sql); } @Override public void invoke (Student value, Context context) throws Exception { ps.setString(1 ,value.getName()); ps.setInt(2 ,value.getAge()); ps.executeUpdate(); } @Override public void close () throws Exception { if (conn != null ){ conn.close(); } if (ps != null ){ ps.close(); } } } }
Connectors JDBC
https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/connectors/jdbc.html
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 public class JDBCDemo { public static void main (String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC); DataStream<Student> studentDs = env.fromElements(new Student (null , "tony2" , 18 )); studentDs.addSink(JdbcSink.sink("insert into student(`id`,`name`,`age`) values (null ,?,?) " ,(ps,value)->{ ps.setString(1 ,value.getName()); ps.setInt(2 ,value.getAge()); },new JdbcConnectionOptions .JdbcConnectionOptionsBuilder() .withDriverName("com.mysql.jdbc.Driver" ) .withUrl("jdbc:mysql://127.0.0.1:3306/db?useSSL=false" ) .withUsername("root" ) .withPassword("root" ) .build())); env.execute(); } @Data @NoArgsConstructor @AllArgsConstructor public static class Student { private Integer id; private String name; private Integer age; } }
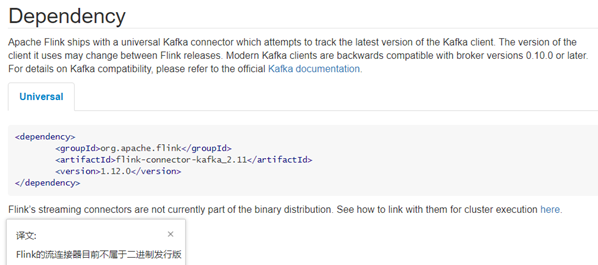
Kafka POM依赖 Flink 里已经提供了一些绑定的 Connector,例如 kafka source 和 sink,Es sink 等。读写kafka、es、rabbitMQ 时可以直接使用相应 connector 的 api 即可,虽然该部分是 Flink 项目源代码里的一部分,但是真正意义上不算作 Flink 引擎相关逻辑,并且该部分没有打包在二进制的发布包里面。所以在提交 Job 时候需要注意, job 代码jar 包中一定要将相应的 connetor 相关类打包进去,否则在提交作业时就会失败,提示找不到相应的类,或初始化某些类异常。
https://ci.apache.org/projects/flink/flink-docs-stable/dev/connectors/kafka.html
参数设置
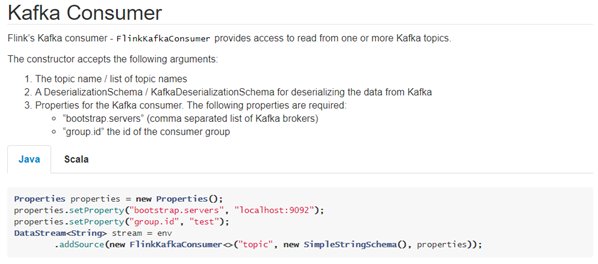
以下参数都必须/建议设置上:
订阅的主题
反序列化规则
消费者属性-集群地址
消费者属性-消费者组id(如果不设置,会有默认的,但是默认的不方便管理)
消费者属性-offset重置规则,如earliest/latest…
动态分区检测(当kafka的分区数变化/增加时,Flink能够检测到!)
如果没有设置Checkpoint,那么可以设置自动提交offset
参数说明
实际的生产环境中可能有这样一些需求,比如:
场景一:有一个 Flink 作业需要将五份数据聚合到一起,五份数据对应五个 kafka topic,随着业务增长,新增一类数据,同时新增了一个 kafka topic,如何在不重启作业的情况下作业自动感知新的 topic。
场景二:作业从一个固定的 kafka topic 读数据,开始该 topic 有 10 个 partition,但随着业务的增长数据量变大,需要对 kafka partition 个数进行扩容,由 10 个扩容到 20。该情况下如何在不重启作业情况下动态感知新扩容的 partition?
针对上面的两种场景,首先需要在构建 FlinkKafkaConsumer 时的 properties 中设置 flink.partition-discovery.interval-millis参数为非负值,表示开启动态发现的开关,以及设置的时间间隔。此时 FlinkKafkaConsumer 内部会启动一个单独的线程定期去 kafka 获取最新的 meta 信息。
针对场景一,还需在构建 FlinkKafkaConsumer 时,topic 的描述可以传一个正则表达式描述的 pattern。每次获取最新 kafka meta 时获取正则匹配的最新 topic 列表。
针对场景二,设置前面的动态发现参数,在定期获取 kafka 最新 meta 信息时会匹配新的 partition。为了保证数据的正确性,新发现的 partition 从最早的位置开始读取。
注意:
开启 checkpoint 时 offset 是 Flink 通过状态 state 管理和恢复的,并不是从 kafka 的 offset 位置恢复。在 checkpoint 机制下,作业从最近一次checkpoint 恢复,本身是会回放部分历史数据,导致部分数据重复消费,Flink 引擎仅保证计算状态的精准一次,要想做到端到端精准一次需要依赖一些幂等的存储系统或者事务操作。
代码实现-Kafka Consumer 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 /** * Desc * 需求:使用flink-connector-kafka_2.12中的FlinkKafkaConsumer消费Kafka中的数据做WordCount * 需要设置如下参数: * 1.订阅的主题 * 2.反序列化规则 * 3.消费者属性-集群地址 * 4.消费者属性-消费者组id(如果不设置,会有默认的,但是默认的不方便管理) * 5.消费者属性-offset重置规则,如earliest/latest... * 6.动态分区检测(当kafka的分区数变化/增加时,Flink能够检测到!) * 7.如果没有设置Checkpoint,那么可以设置自动提交offset,后续学习了Checkpoint会把offset随着做Checkpoint的时候提交到Checkpoint和默认主题中 */ public class KafkaConsumerDemo { public static void main(String[] args) throws Exception { // 0.env StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC); // source Properties props = new Properties(); props.setProperty("bootstrap.servers", "master:9092"); props.setProperty("group.id", "flink"); // 有offset记录从记录位置开始消费, // latest-->没有记录从最新的或最后的消息开始消费 // earliest-->有offset记录从记录位置开始消费,没有记录从最早的或最开始的消息开始消费 props.setProperty("auto.offset.reset","latest"); //会开启一个后台线程每隔5s检测一下Kafka的分区情况,实现动态分区检测 props.setProperty("flink.partition-discovery.interval-millis","5000"); // 自动提交(提交到默认主题) props.setProperty("enable.auto.commit", "true"); // 自动提交的时间 props.setProperty("auto.commit.interval.ms", "2000"); FlinkKafkaConsumer kafkaSource = new FlinkKafkaConsumer<String>("flink_kafka", new SimpleStringSchema(), props); // 使用kafkaSource DataStream kafkaDS = env.addSource(kafkaSource); // transformation // sink kafkaDS.print(); env.execute(); } }
代码实现-Kafka Producer 将Flink集合中的数据通过自定义Sink保存到Kafka
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 public class KafkaSinkDemo { public static void main (String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC); Properties props = new Properties (); props.setProperty("bootstrap.servers" , "master:9092" ); props.setProperty("group.id" , "flink" ); props.setProperty("auto.offset.reset" ,"latest" ); props.setProperty("flink.partition-discovery.interval-millis" ,"5000" ); props.setProperty("enable.auto.commit" , "true" ); props.setProperty("auto.commit.interval.ms" , "2000" ); FlinkKafkaConsumer kafkaSource = new FlinkKafkaConsumer <String>("flink_kafka" , new SimpleStringSchema (), props); DataStream kafkaDS = env.addSource(kafkaSource); SingleOutputStreamOperator etlDS = kafkaDS.filter(new FilterFunction <String>() { @Override public boolean filter (String value) throws Exception { return value.contains("success" ); } }); etlDS.print(); Properties props2 = new Properties (); props2.setProperty("bootstrap.servers" , "master:9092" ); etlDS.addSink(new FlinkKafkaProducer <String>("flink_kafka2" , new SimpleStringSchema (), props2)); env.execute(); } @Data @NoArgsConstructor @AllArgsConstructor public static class Student { private Integer id; private String name; private Integer age; } }