
flink学习笔记02-flink部署与应用
flink集群架构
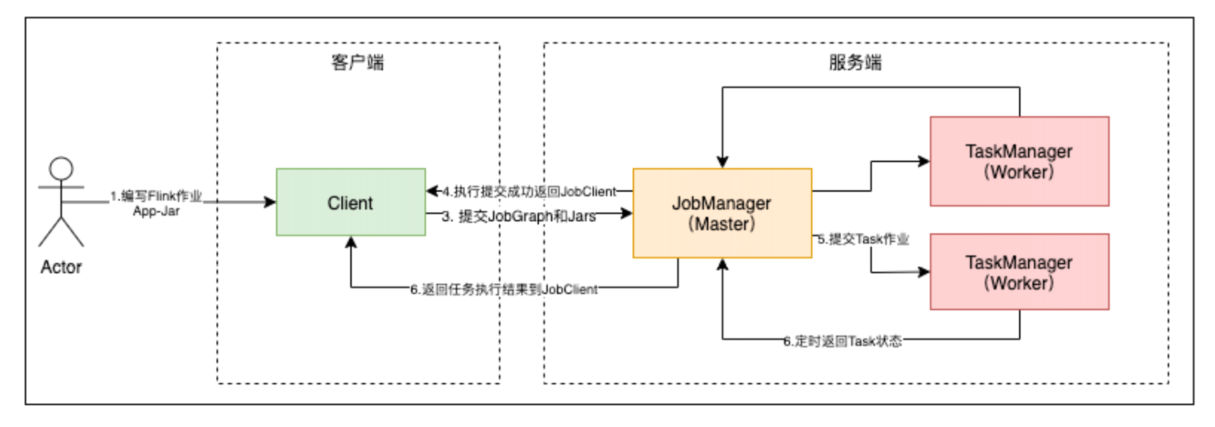
flink集群架构由JobManager, TaskManager 以及Client组成。
- JobManger: 管理节点,每个集群至少一个,管理整个集群计算资源,Job管理与调度执行,以及Checkpoint协调。
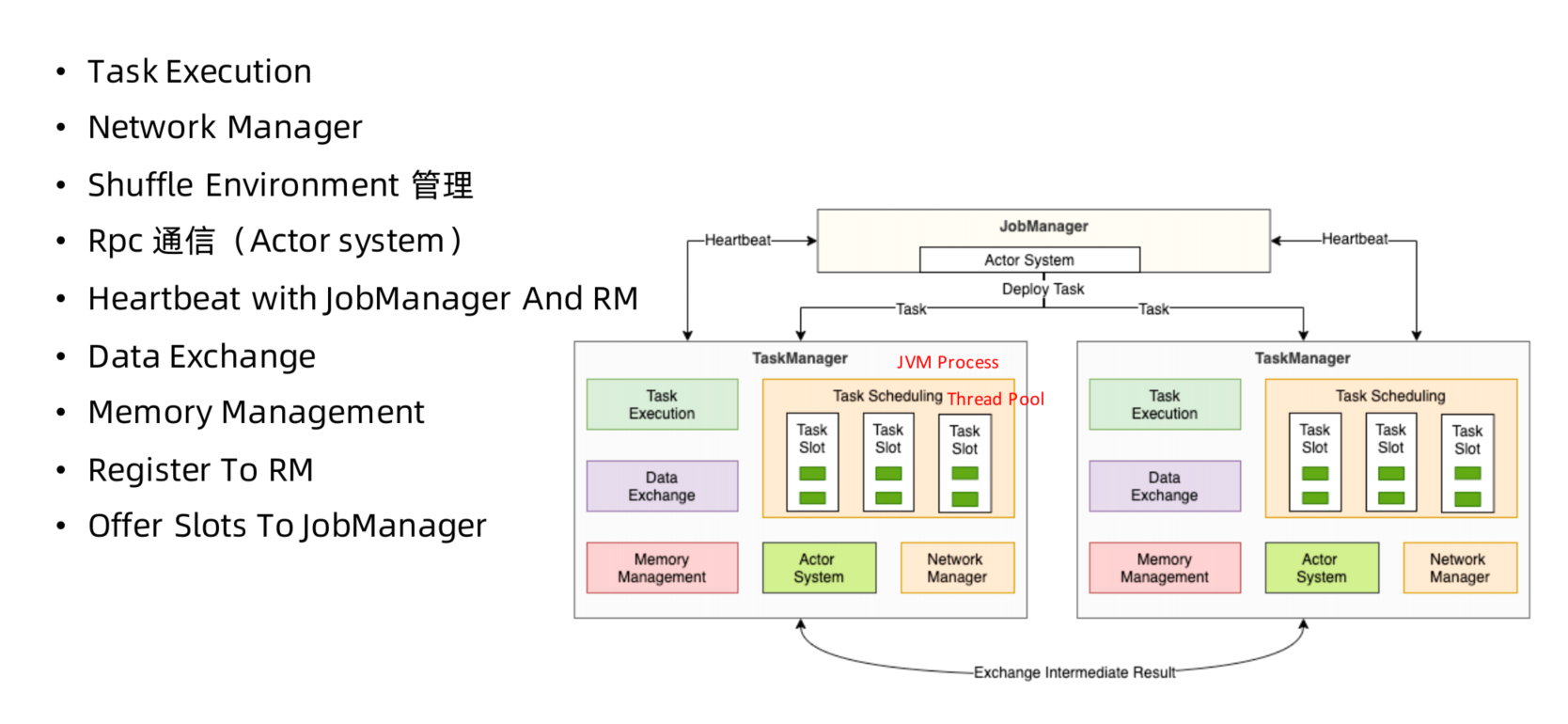
- TaskManager: 每个集群有多个TM,负责计算资源提供。
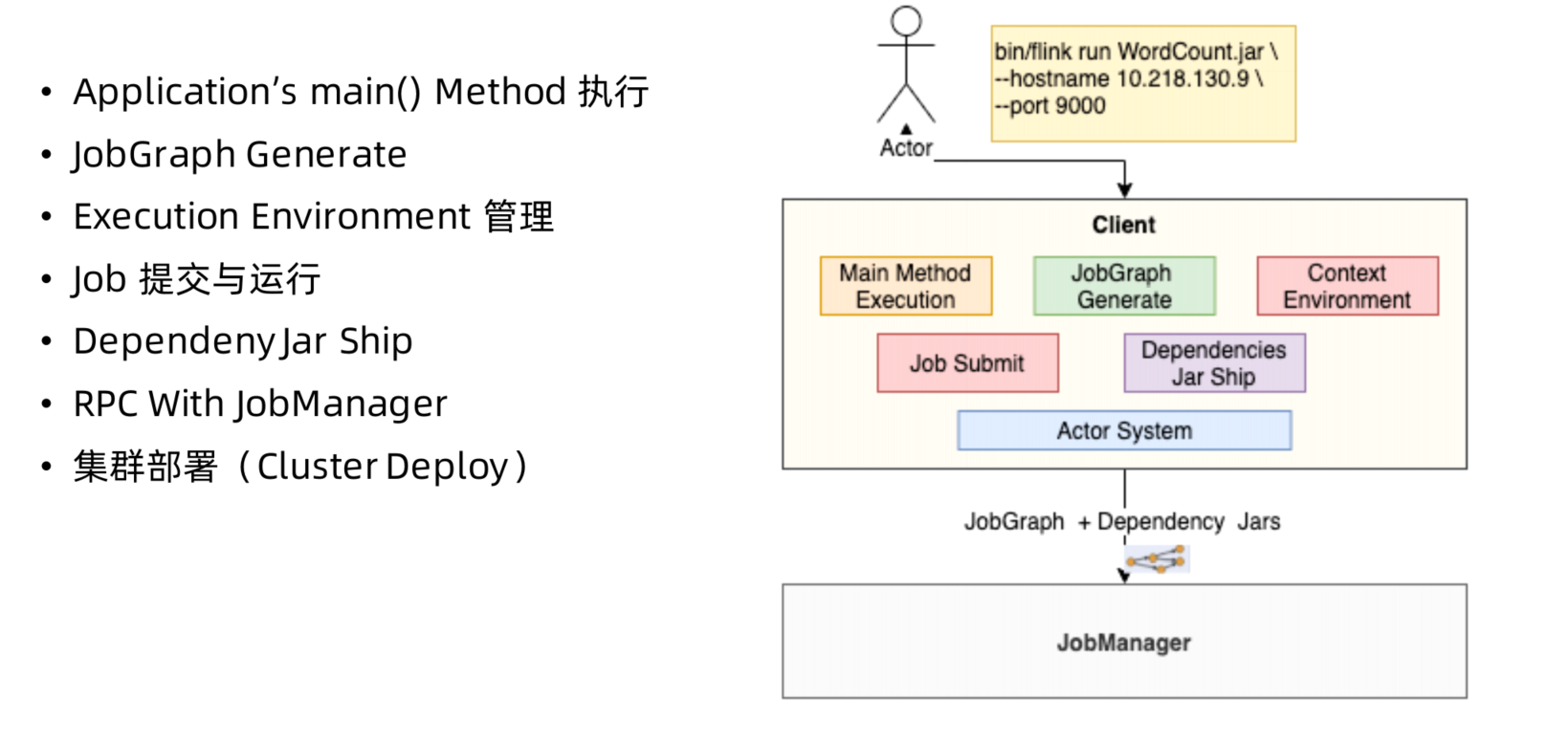
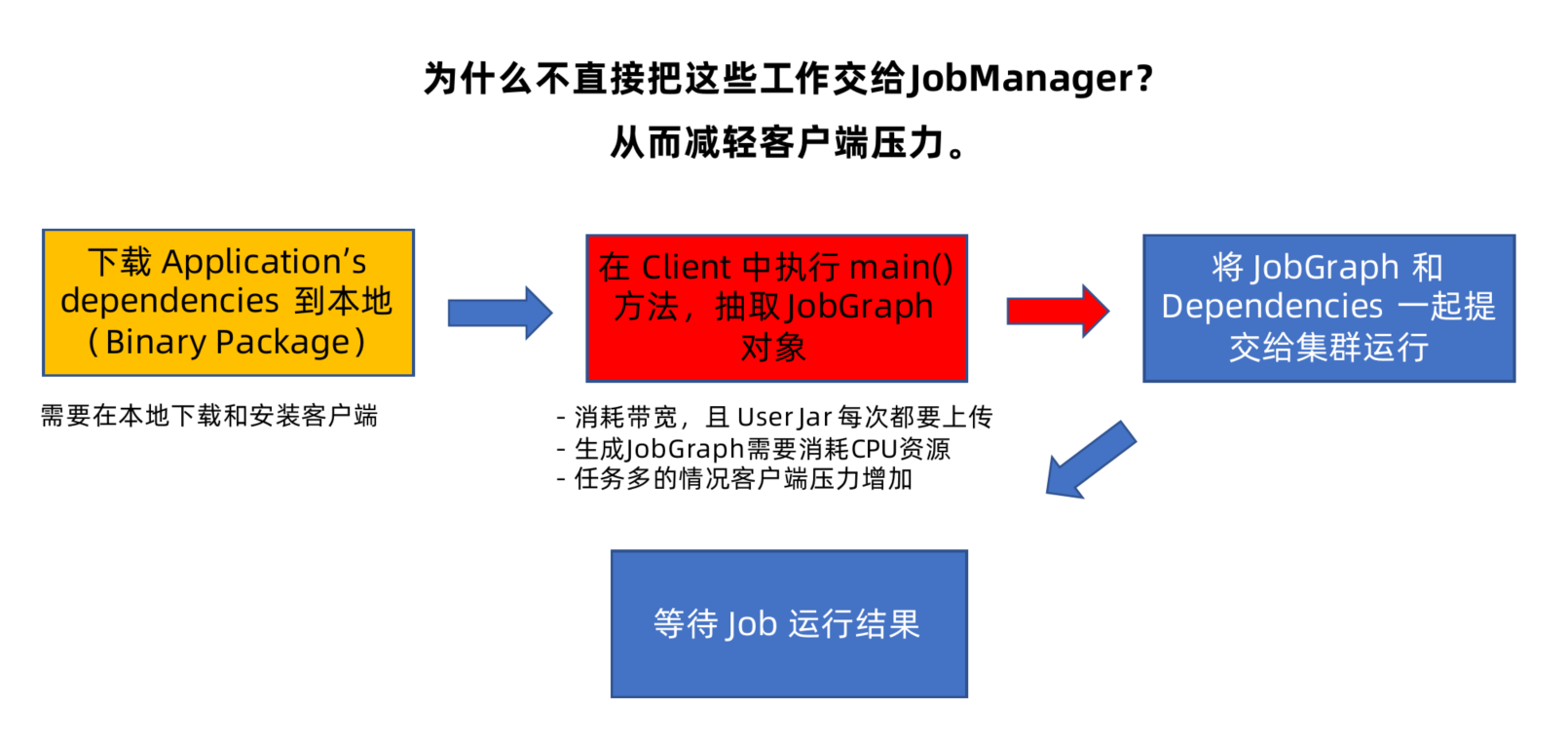
- Client: 本地执行应用main()方法解析JobGraph对象,并最终将JobGraph提交到JobManager运行,同时监控Job执行的状态。
JobManger

TaskManager
client
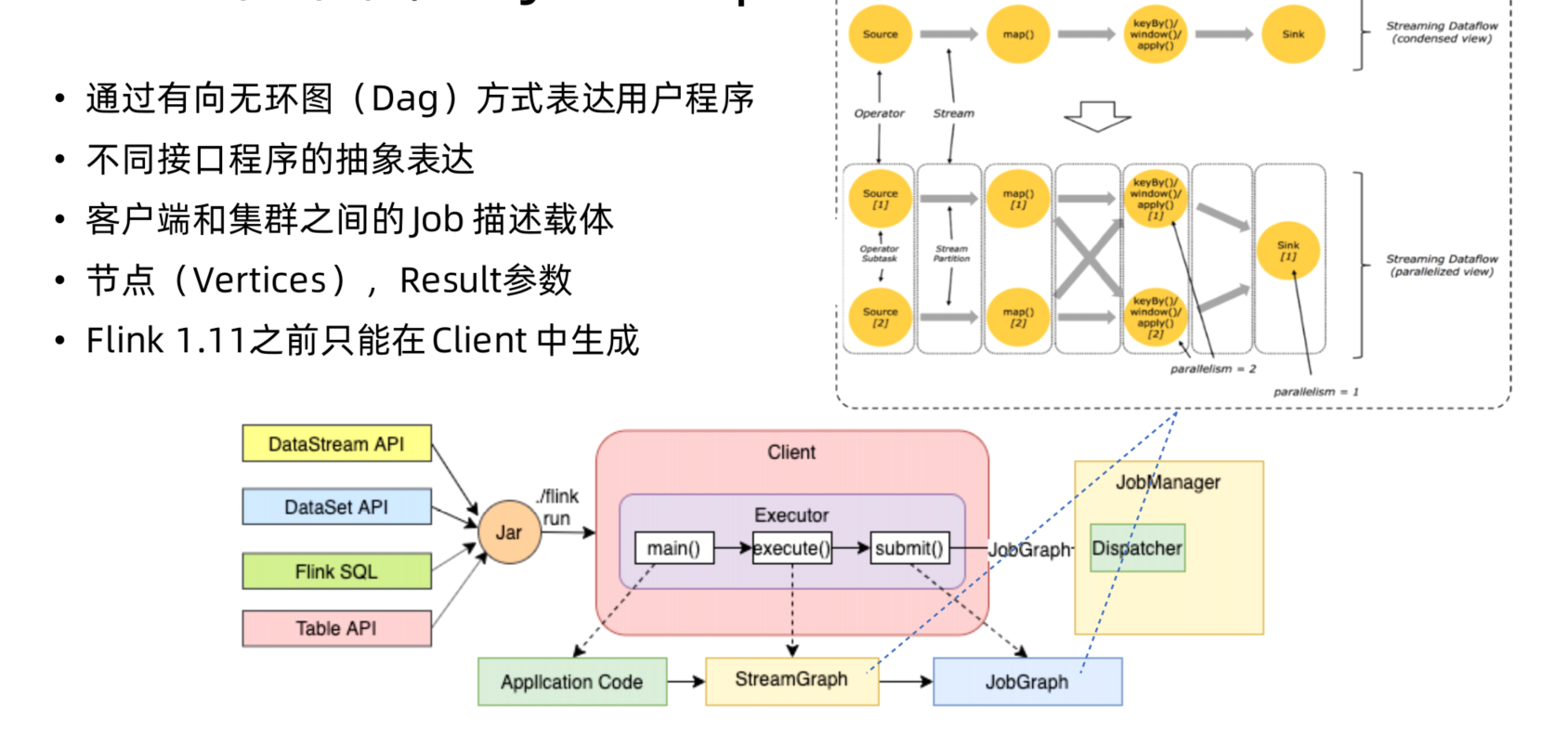
JobGraph
flink集群部署模式
flink集群部署模式对比
根据以下两种条件将集群部署模式分为三种类型:
1.集群的生命周期和资源隔离
2.根据程序main()方法执行在client还是JobManager
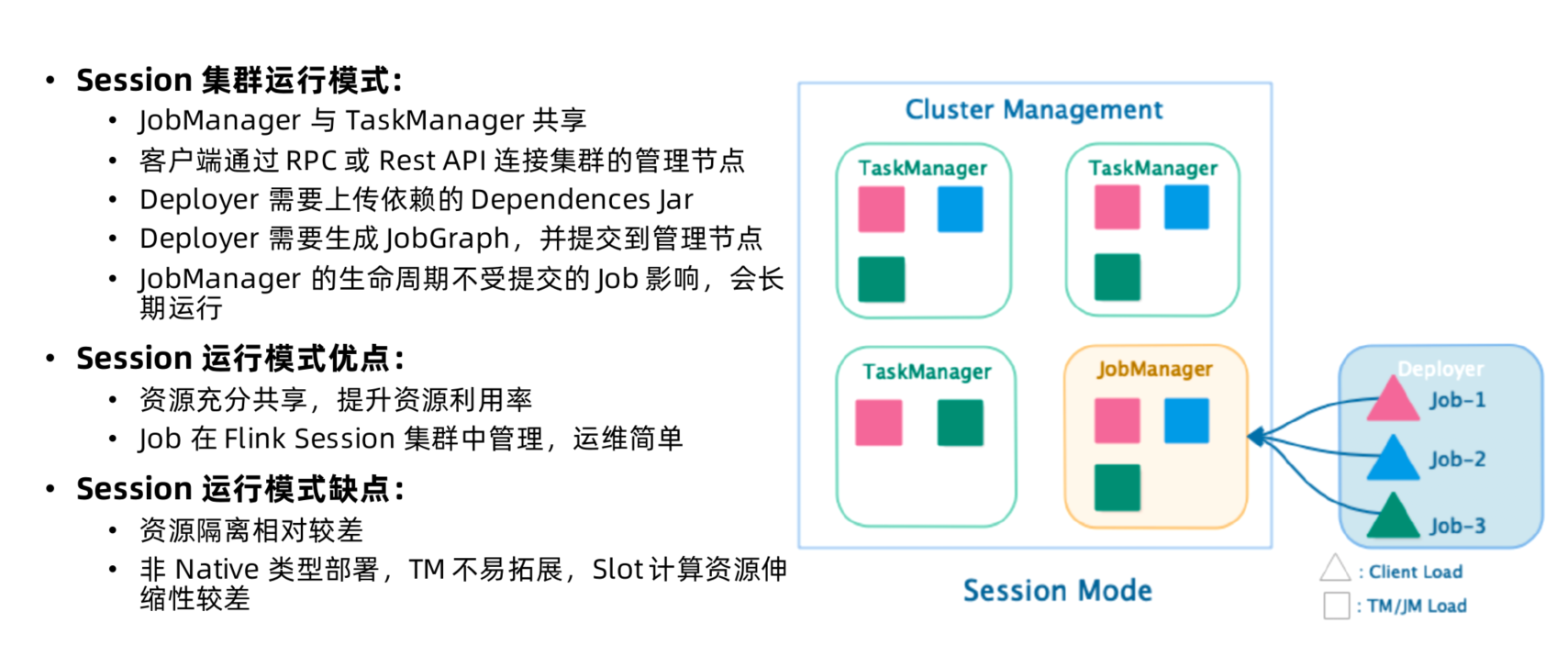
- Session Mode
- 共享JobManager和TaskManager, 所有提交的Job都在一个runtime中运行
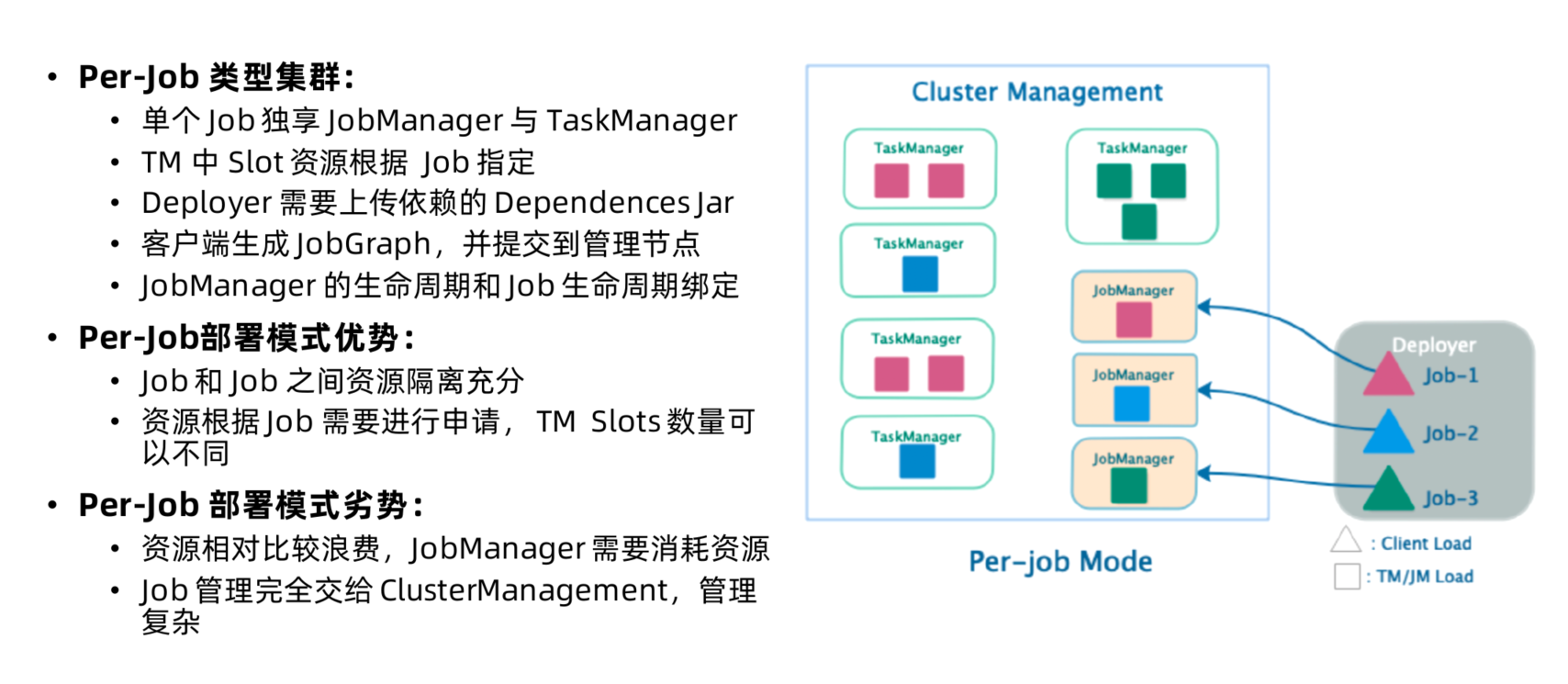
- Per-Job Mode
- 独享JobManager与TaskManager, 好比为每个Job单独启动一个Runtime
- Application Mode (1.11版本提出)
- Application的main() 运行在Cluster上,而不在客户端
- 每个Application对应一个Runtime, Application中科院含有多个Job
Session 集群运行模式
Per-Job集群运行模式
Session集群和Per-Job类型集群问题
Application Mode集群运行模式

集群资源管理器支持
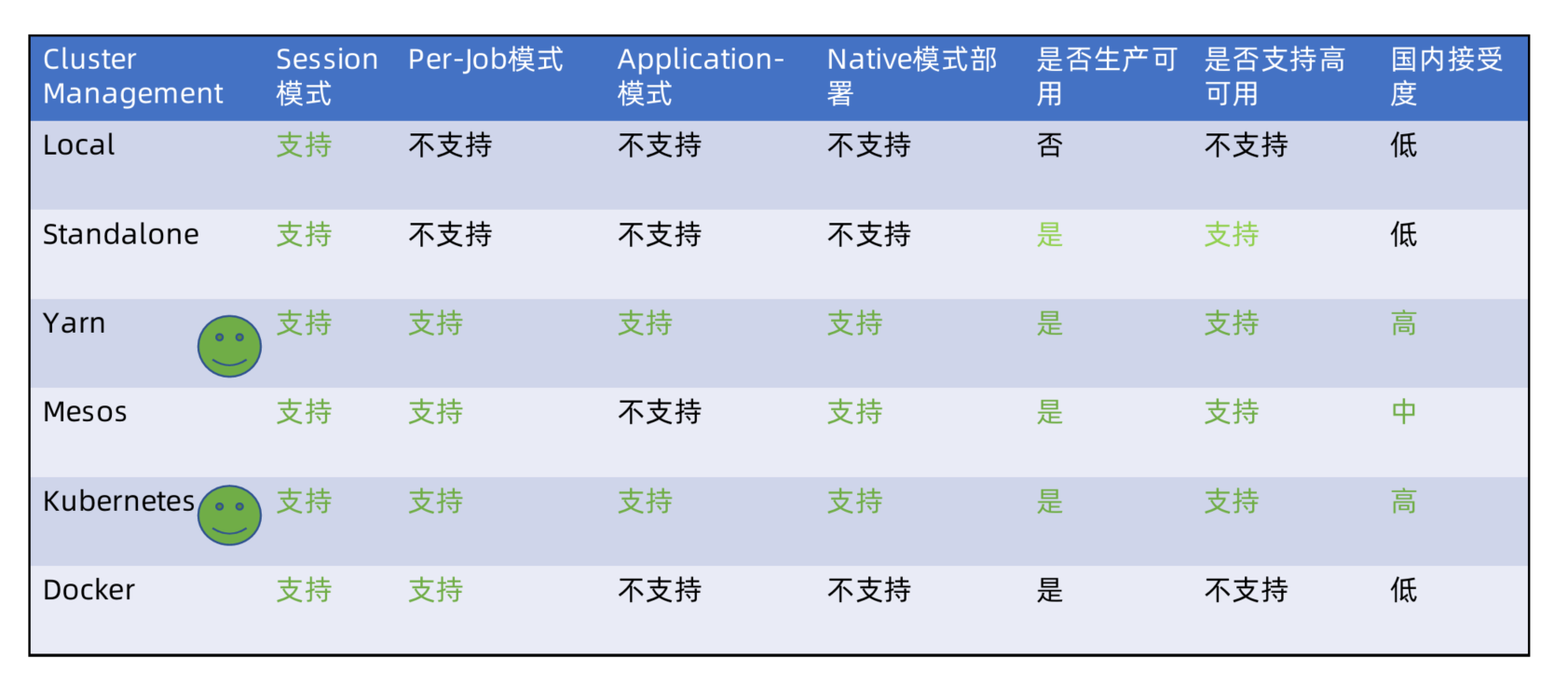
Cluster Management支持
flink支持以下资源管理器部署集群:
- Standalone
- Hadoop Yarn
- Apache Mesos
- Docker
- Kubernetes

flink集群部署对比
Native集群部署
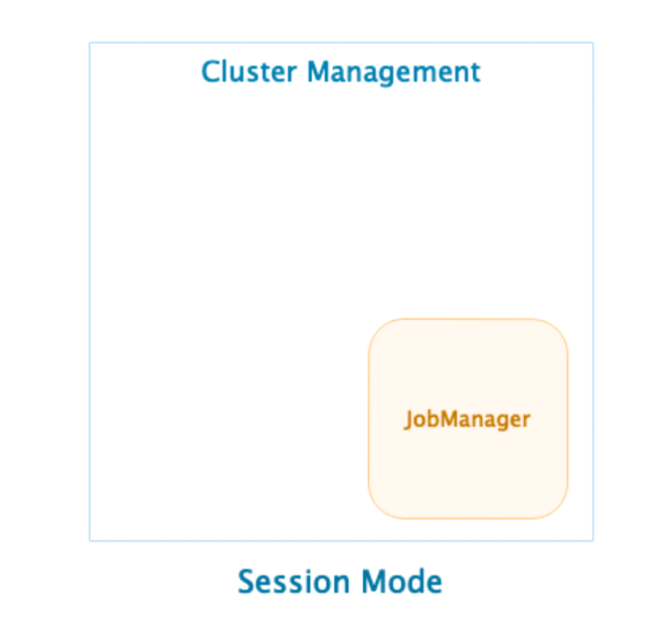
- 当在ClusterManagement上启动Session集群时,只启动JobManager实例,不启动TaskManager
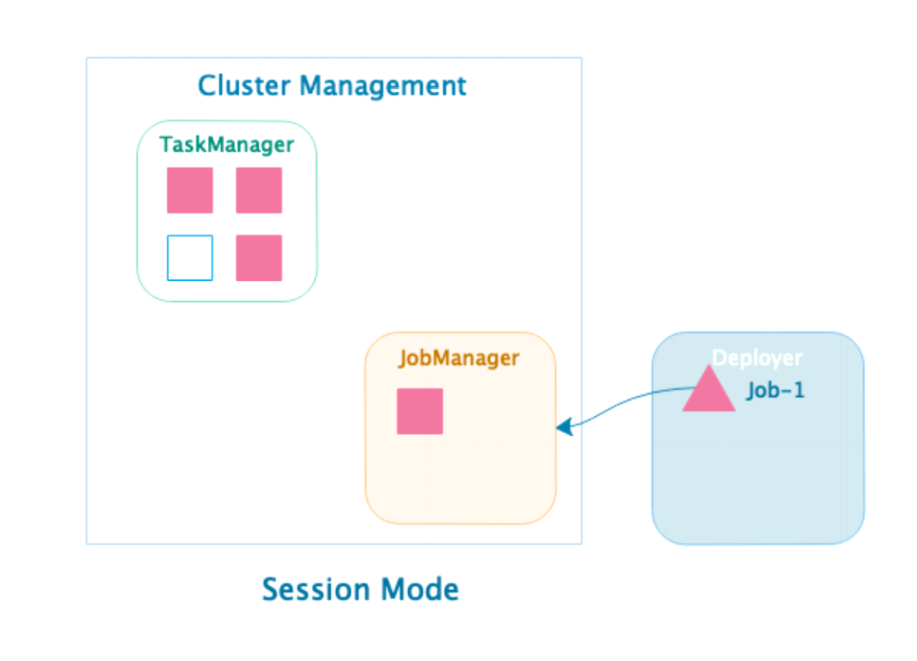
- 提交Job-1后根据Job的资源申请,动态启动TaskManager满足计算需求。
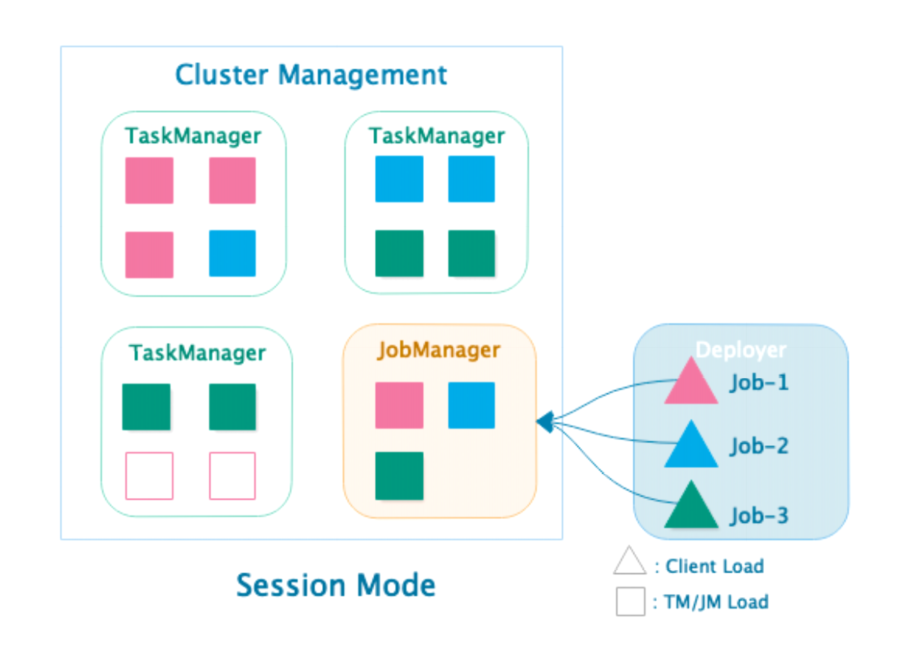
- 提交Job-2, Job-3后,再次向ClusterManagement中申请TM资源。
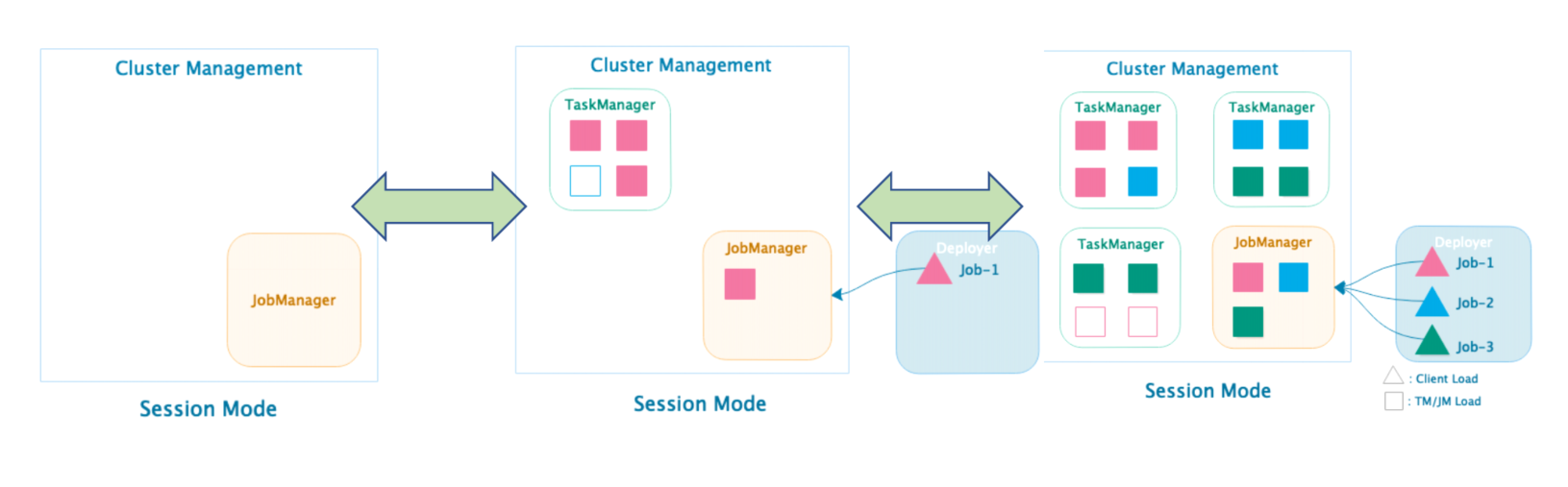
- Session 集群根据实际提交的Job资源动态申请和启动TaskManager计算资源。
- 支持Native部署模式的有Yarn, Kubernetes, Mesos资源管理器。
- Standalone不支持Native部署。
Standalone原理剖析与实践
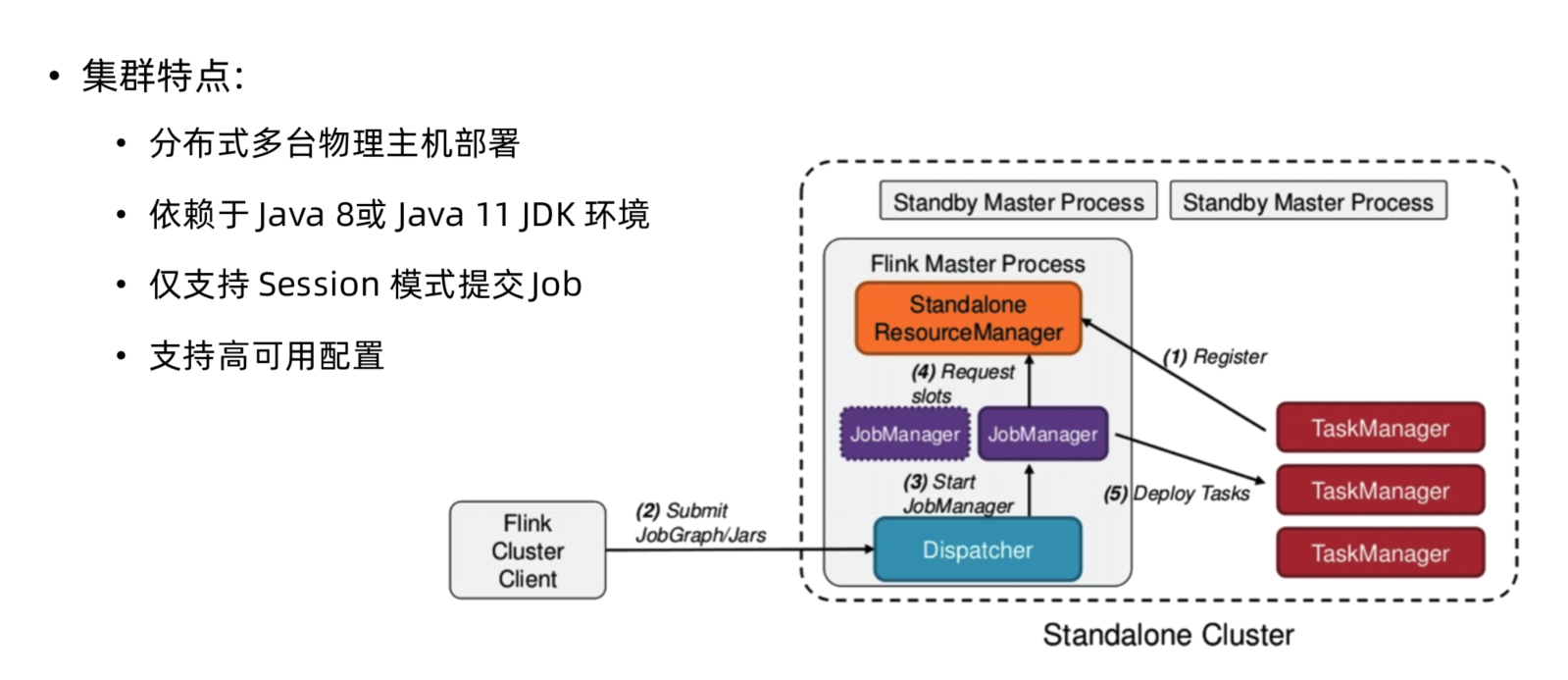

Standalone(单机) 集群部署步骤
下载安装flink安装包或者通过源码编译生成
1
wget https://archive.apache.org/dist/flink/flink-1.11.1/flink-1.11.1-bin-scala_2.11.tgz
解压安装包
1
tar -zxf flink-1.11.1-bin-scala_2.11.tgz
启动flink集群
1
2cd flink-1.11.1
bin/start-cluster.sh
Standalone(多机) 集群部署步骤
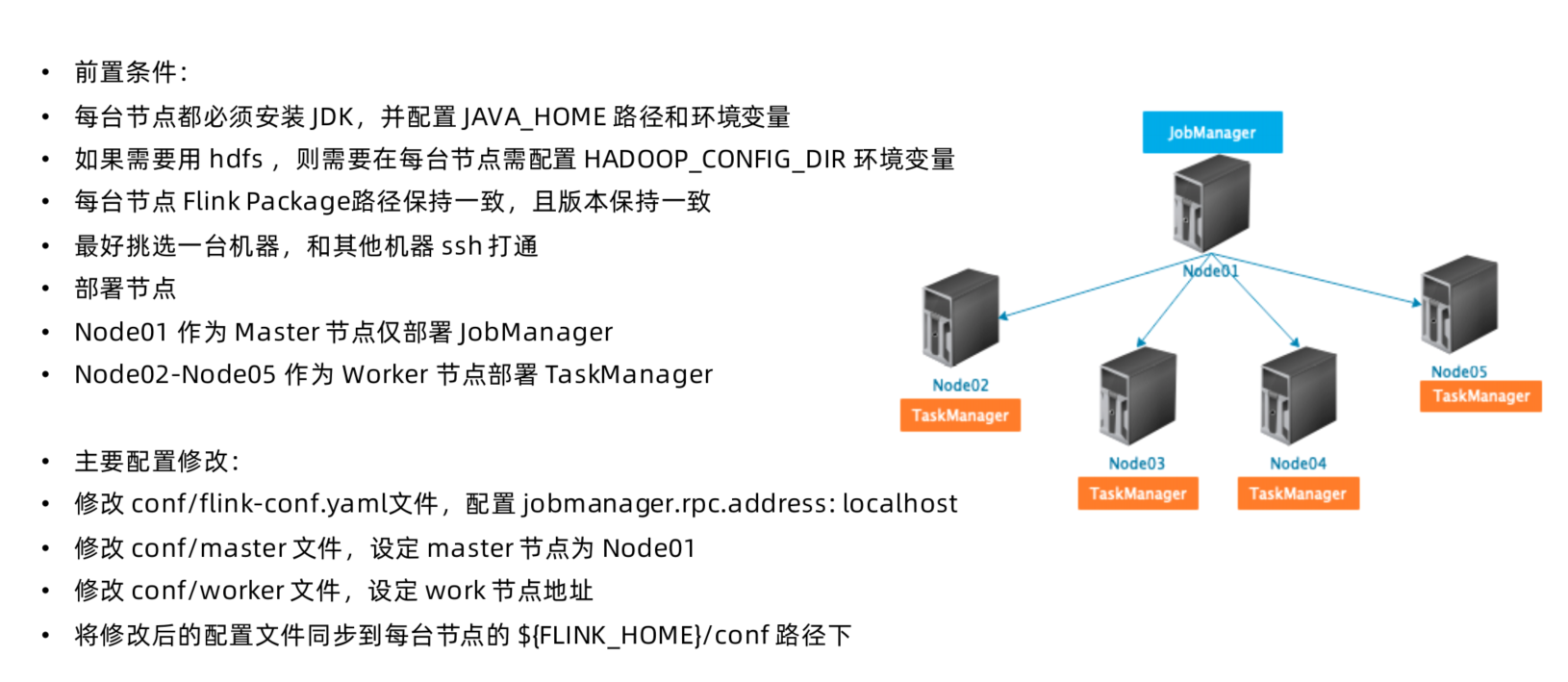
flink on Yarn 原理剖析与实践
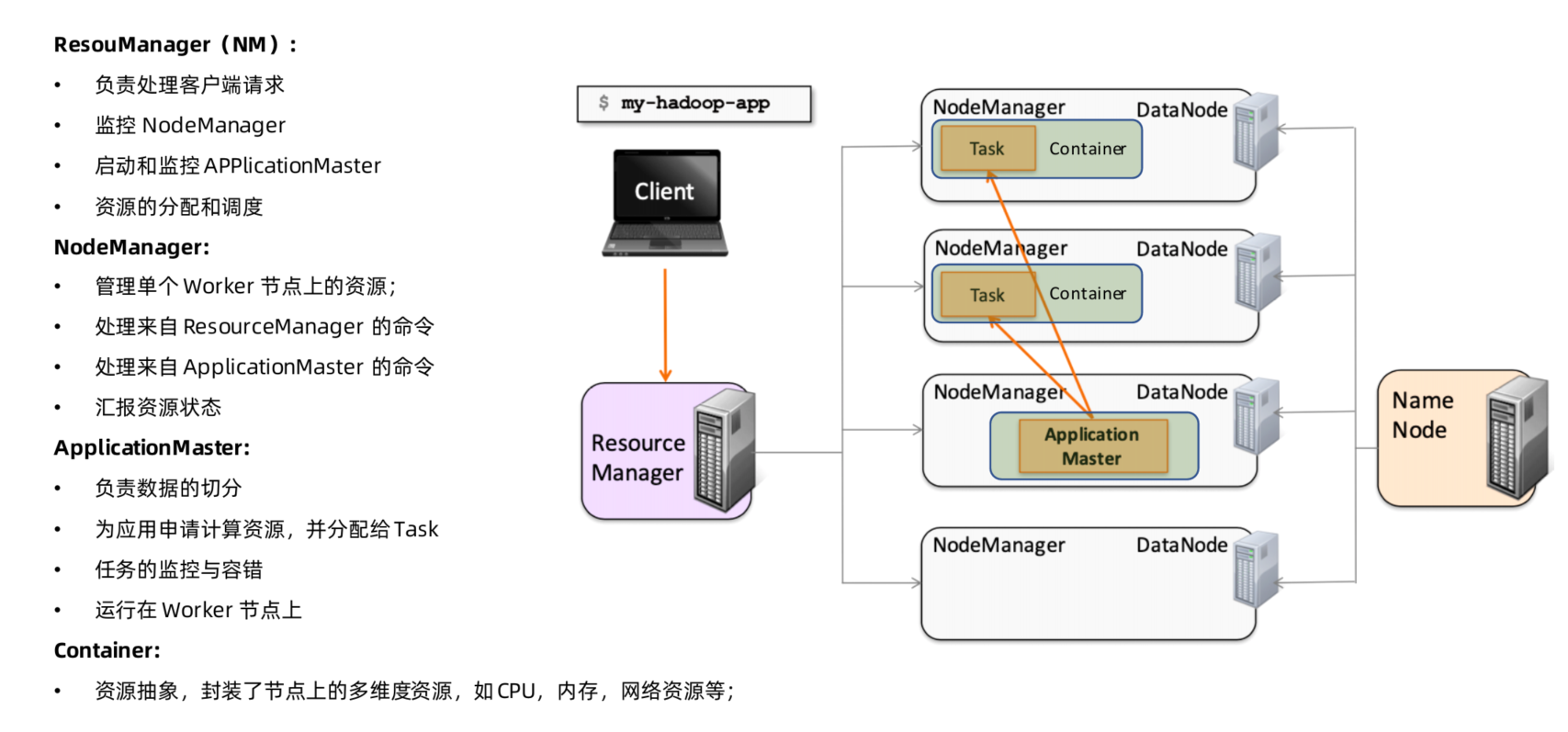
Yarn 集群架构原理
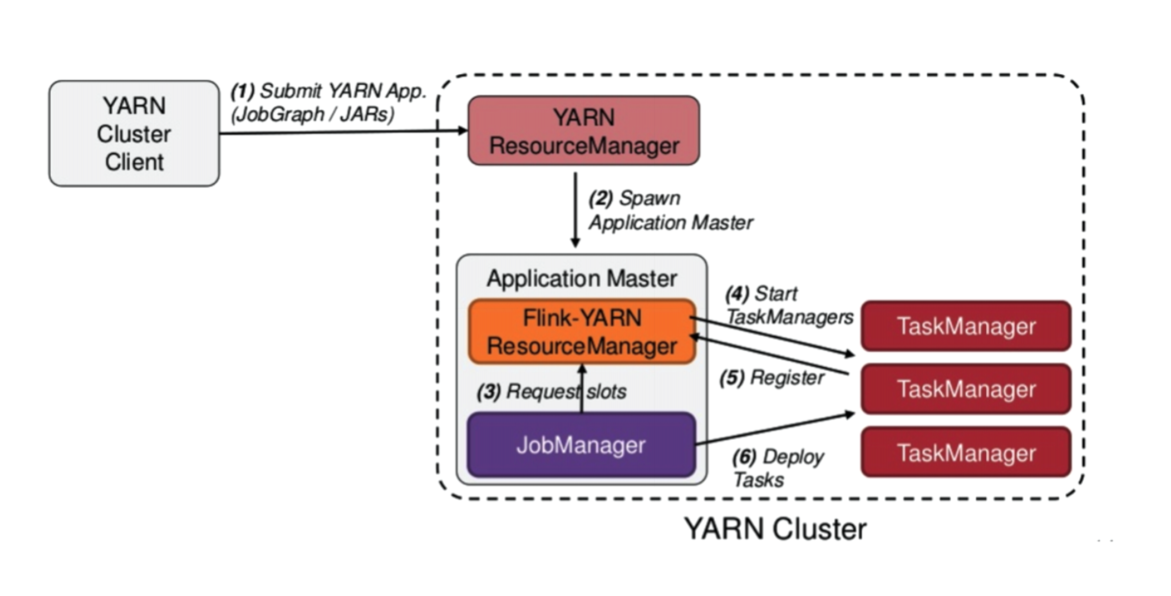
flink on Yarn- Session模式
- 多JobManager 共享 Dispathcher 和 YarnResourceManager
- 支持Native模式,TM动态申请

flink on Yarn- Per-Job模式
- 单个JobManager独享YarnResourceManager和Dispatcher
- Application Master与Flink Master节点处于同一个Container
flink on Yarn 优势与劣势
主要优势:
- 与现有大数据平台无缝对接(Hadoop2.4+)
- 部署集群与任务提交都非常简单
- 资源管理统一通过Yarn管理,提升整体资源利用率
- 基于Native方式,TaskManager资源按需申请和启动,防止资源浪费
- 容错保证借助于Hadoop Yarn提供的自动failover机制,能保证JobManager, TaskManager节点异常恢复
主要劣势:
- 资源隔离问题,尤其是网络资源的隔离,Yarn做的还不够完善
- 离线和实时作业同时运行相互干扰等问题需要重视
- Kerberos认证超时问题导致Checkpoint无法持久化
flink on Yarn 部署实践
环境要求
- Apache Hadoop 2.4.1及以上
- HDFS (Hadoop Distributed File System) 环境
- Hadoop依赖包
环境配置
- 下载和解压安装包(参考Standalone模式)
- 配置HADOOP_CONFIG_DIR环境变量
1 | export HADOOP_HOME=/usr/hdp/2.6.4.0-91/hadoop |
- 如果HADOOP_CLASSPATH配置后,作业执行还报Hadoop依赖找不到错误,可以到如下地址下载,并放置在lib路径中:
1 | cd lib/ |
基于Session Mode部署
1 | ./bin/yarn-session.sh -tm 1028 -s 8 |
可配置的运行参数如下:
1 | Usage: |
Attach to an existing Session
1 | ./bin/yarn-session.sh -id application_1463870264508_0029 |
提交Flink作业到指定Session集群
1 | 上传测试文件 |
停止集群服务
方式1:
1 | echo "stop" | ./bin/yarn-session.sh -id application_1597152309776_0008 |
方式2:
1 | 找到作业对应的ApplicationID |
flink在Yarn HA模式下报错
yarn 非ha的时候是没问题的
在HA模式下,发现报错,信息如下:
1 | java.lang.RuntimeException: java.lang.ClassNotFoundException: Class org.apache.hadoop.yarn.client.RequestHedgingRMFailoverProxyProvider not found |
修改yarn的配置:
1 | yarn.client.failover-proxy-provider=org.apache.hadoop.yarn.client.ConfiguredRMFailoverProxyProvider |
基于Per-Job Mode部署
直接运行如下命令即可提交作业:
1 | ./bin/flink run -m yarn-cluster ./examples/batch/WordCount.jar |
Detach 模式:
1 | ./bin/flink run -m yarn-cluster -d ./examples/batch/WordCount.jar |
基于Application Mode部署
- 通过从本地上传Dependencies和User Application Jar
1 | ./bin/flink run-application -t yarn-application \ |
- 通过从HDFS获取Dependencies和本地上传User Application Jar
1 | ./bin/flink run-application -t yarn-application \ |
- 通过指定yarn.provided.lib.dirs参数部署,将Flink Binary包和Application Jar都同时从HDFS上获取
1 | ./bin/flink run-application -t yarn-application \ |
flink on Kuberneter原理与实践
待补充
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 我的技术小站!
相关推荐




评论




