
flink学习笔记04-flink高级API
Flink四大基石
Flink之所以能这么流行,离不开它最重要的四个基石:Checkpoint、State、Time、Window。

Checkpoint
这是Flink最重要的一个特性。
Flink基于Chandy-Lamport算法实现了一个分布式的一致性的快照,从而提供了一致性的语义。
Chandy-Lamport算法实际上在1985年的时候已经被提出来,但并没有被很广泛的应用,而Flink则把这个算法发扬光大了。
Spark最近在实现Continue streaming,Continue streaming的目的是为了降低处理的延时,其也需要提供这种一致性的语义,最终也采用了Chandy-Lamport这个算法,说明Chandy-Lamport算法在业界得到了一定的肯定。
State
提供了一致性的语义之后,Flink为了让用户在编程时能够更轻松、更容易地去管理状态,还提供了一套非常简单明了的State API,包括ValueState、ListState、MapState,BroadcastState。
Time
除此之外,Flink还实现了Watermark的机制,能够支持基于事件的时间的处理,能够容忍迟到/乱序的数据。
Window
另外流计算中一般在对流数据进行操作之前都会先进行开窗,即基于一个什么样的窗口上做这个计算。Flink提供了开箱即用的各种窗口,比如滑动窗口、滚动窗口、会话窗口以及非常灵活的自定义的窗口。
Flink-Window操作
为什么需要Window
在流处理应用中,数据是连续不断的,有时我们需要做一些聚合类的处理,例如:在过去的1分钟内有多少用户点击了我们的网页。
在这种情况下,我们必须定义一个窗口(window),用来收集最近1分钟内的数据,并对这个窗口内的数据进行计算。
Window的分类
按照time和count分类
- time-window:时间窗口:根据时间划分窗口,如:每xx分钟统计最近xx分钟的数据
- count-window:数量窗口:根据数量划分窗口,如:每xx个数据统计最近xx个数据

按照slide和size分类
窗口有两个重要的属性: 窗口大小size和滑动间隔slide,根据它们的大小关系可分为:
tumbling-window:滚动窗口:size=slide,如:每隔10s统计最近10s的数据
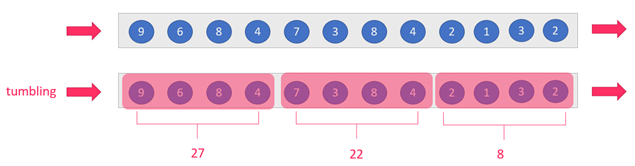
sliding-window:滑动窗口:size>slide,如:每隔5s统计最近10s的数据
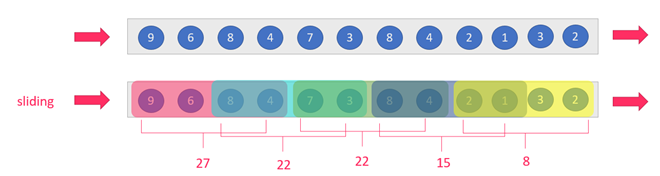
注意:当size<slide的时候,如每隔15s统计最近10s的数据,那么中间5s的数据会丢失,所有开发中不用
总结
按照上面窗口的分类方式进行组合,可以得出如下的窗口:
- 基于时间的滚动窗口tumbling-time-window—用的较多
- 基于时间的滑动窗口sliding-time-window—用的较多
- 基于数量的滚动窗口tumbling-count-window—用的较少
- 基于数量的滑动窗口sliding-count-window—用的较少
注意:Flink还支持一个特殊的窗口:Session会话窗口,需要设置一个会话超时时间,如30s,则表示30s内没有数据到来,则触发上个窗口的计算
Window的API
window和windowAll

- 使用keyby的流,应该使用window方法
- 未使用keyby的流,应该调用windowAll方法
WindowAssigner
window/windowAll 方法接收的输入是一个 WindowAssigner, WindowAssigner 负责将每条输入的数据分发到正确的 window 中,Flink提供了很多各种场景用的WindowAssigner:
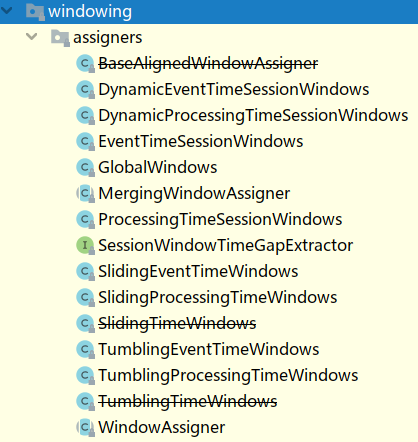
如果需要自己定制数据分发策略,则可以实现一个 class,继承自 WindowAssigner。
案例演示
基于时间的滚动和滑动窗口
需求1:每5秒钟统计一次,最近5秒钟内,各个路口通过红绿灯汽车的数量—基于时间的滚动窗口
需求2:每5秒钟统计一次,最近10秒钟内,各个路口通过红绿灯汽车的数量—基于时间的滑动窗口
示例代码:
1 | public class WindowDemo01_TimeWindow { |
基于数量的滚动和滑动窗口
需求1:统计在最近5条消息中,各自路口通过的汽车数量,相同的key每出现5次进行统计—基于数量的滚动窗口
需求2:统计在最近5条消息中,各自路口通过的汽车数量,相同的key每出现3次进行统计—基于数量的滑动窗口
示例代码:
1 | public class WindowDemo02_CountWindow { |
会话窗口
- 设置会话超时时间为10s,10s内没有数据到来,则触发上个窗口的计算
示例代码:
1 | public class WindowDemo03_SessionWindow { |
Flink-Time与Watermaker
Time分类
在Flink的流式处理中,会涉及到时间的不同概念,如下图所示:
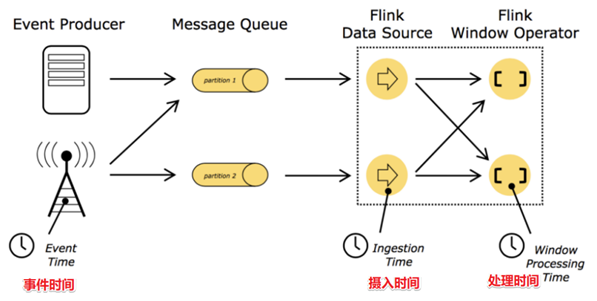
- 事件时间EventTime: 事件真真正正发生产生的时间
- 摄入时间IngestionTime: 事件到达Flink的时间
- 处理时间ProcessingTime: 事件真正被处理/计算的时间
Watermaker水印机制/水位线机制
Watermaker就是给数据再额外的加的一个时间列,Watermaker = 当前窗口的最大的事件时间 - 最大允许的延迟时间或乱序时间
图解watermaker
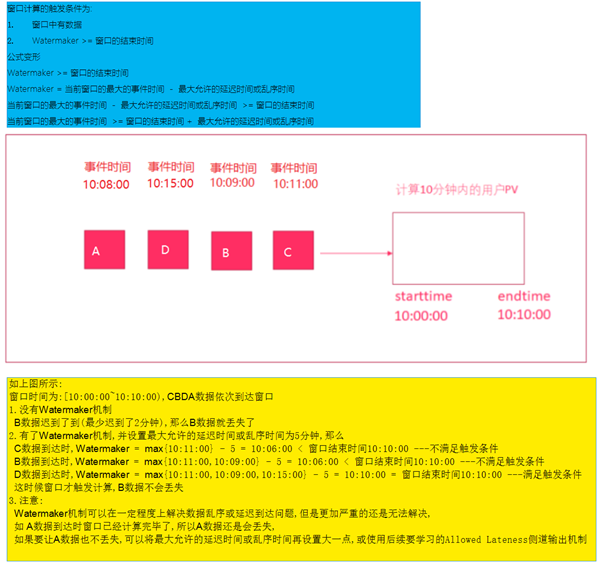
watermaker案例演示
需求
有订单数据,格式为: (订单ID,用户ID,时间戳/事件时间,订单金额)
要求每隔5s,计算5秒内,每个用户的订单总金额
并添加Watermaker来解决一定程度上的数据延迟和数据乱序问题。
示例代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75public class WatermakerDemo01 {
public static void main(String[] args) throws Exception {
//1.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2.Source
//模拟实时订单数据(数据有延迟和乱序)
DataStream<Order> orderDS = env.addSource(new SourceFunction<Order>() {
private boolean flag = true;
public void run(SourceContext<Order> ctx) throws Exception {
Random random = new Random();
while (flag) {
String orderId = UUID.randomUUID().toString();
int userId = random.nextInt(3);
int money = random.nextInt(100);
//模拟数据延迟和乱序!
long eventTime = System.currentTimeMillis() - random.nextInt(5) * 1000;
ctx.collect(new Order(orderId, userId, money, eventTime));
TimeUnit.SECONDS.sleep(1);
}
}
public void cancel() {
flag = false;
}
});
//3.Transformation
//-告诉Flink要基于事件时间来计算!
//env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);//新版本默认就是EventTime
//-告诉Flnk数据中的哪一列是事件时间,因为Watermaker = 当前最大的事件时间 - 最大允许的延迟时间或乱序时间
/*DataStream<Order> watermakerDS = orderDS.assignTimestampsAndWatermarks(
new BoundedOutOfOrdernessTimestampExtractor<Order>(Time.seconds(3)) {//最大允许的延迟时间或乱序时间
@Override
public long extractTimestamp(Order element) {
return element.eventTime;
//指定事件时间是哪一列,Flink底层会自动计算:
//Watermaker = 当前最大的事件时间 - 最大允许的延迟时间或乱序时间
}
});*/
DataStream<Order> watermakerDS = orderDS
.assignTimestampsAndWatermarks(
WatermarkStrategy.<Order>forBoundedOutOfOrderness(Duration.ofSeconds(3))
.withTimestampAssigner((event, timestamp) -> event.getEventTime())
);
//代码走到这里,就已经被添加上Watermaker了!接下来就可以进行窗口计算了
//要求每隔5s,计算5秒内(基于时间的滚动窗口),每个用户的订单总金额
DataStream<Order> result = watermakerDS
.keyBy(Order::getUserId)
//.timeWindow(Time.seconds(5), Time.seconds(5))
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.sum("money");
//4.Sink
result.print();
//5.execute
env.execute();
}
public static class Order {
private String orderId;
private Integer userId;
private Integer money;
private Long eventTime;
}
}
Flink-状态管理
无状态计算和有状态计算
无状态计算
不需要考虑历史数据
相同的输入得到相同的输出就是无状态计算, 如map/flatMap/filter….

有状态计算
需要考虑历史数据
相同的输入得到不同的输出/不一定得到相同的输出,就是有状态计算,如:sum/reduce


状态的分类
Managed State & Raw State

从Flink是否接管角度:可以分为Managed State(托管状态) ,Raw State(原始状态),两者的区别如下:
- 从状态管理方式的方式来说,Managed State 由 Flink Runtime 管理,自动存储,自动恢复,在内存管理上有优化;而 RawState 需要用户自己管理,需要自己序列化,Flink 不知道 State 中存入的数据是什么结构,只有用户自己知道,需要最终序列化为可存储的数据结构。
- 从状态数据结构来说,Managed State 支持已知的数据结构,如 Value、List、Map 等。而 Raw State只支持字节数组 ,所有状态都要转换为二进制字节数组才可以。
- 从推荐使用场景来说,Managed State 大多数情况下均可使用,而 Raw State 是当 Managed State 不够用时,比如需要自定义 Operator 时,才会使用 Raw State。
- 在实际生产中,都只推荐使用ManagedState
Keyed State & Operator State

Managed State 分为两种,Keyed State 和 Operator State (Raw State都是Operator State)
Keyed State
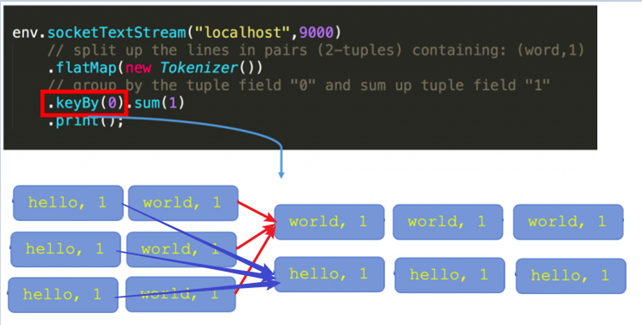
在Flink Stream模型中,Datastream 经过 keyBy 的操作可以变为 KeyedStream。
Keyed State是基于KeyedStream上的状态。这个状态是跟特定的key绑定的,对KeyedStream流上的每一个key,都对应一个state,如stream.keyBy(…)
KeyBy之后的State,可以理解为分区过的State,每个并行keyed Operator的每个实例的每个key都有一个Keyed State,即
Operator State
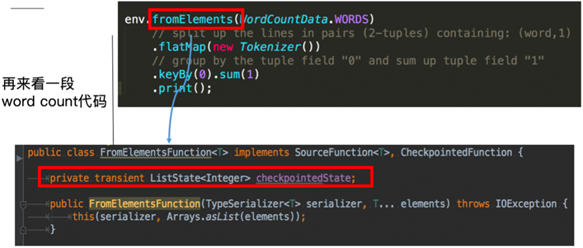
这里的fromElements会调用FromElementsFunction的类,其中就使用了类型为 list state 的 operator state
Operator State又称为 non-keyed state,与Key无关的State,每一个 operator state 都仅与一个 operator 的实例绑定。
Operator State 可以用于所有算子,但一般常用于 Source
State代码示例
Keyed State
下图就 word count 的 sum 所使用的StreamGroupedReduce类为例讲解了如何在代码中使用 keyed state:
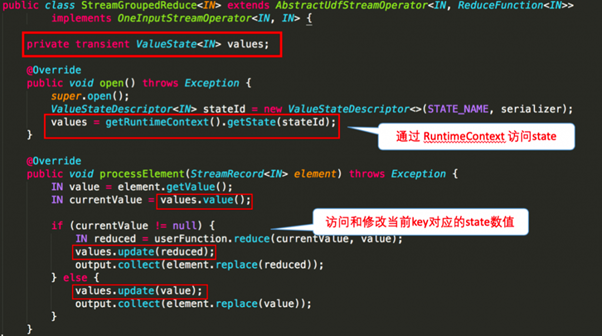
使用KeyState中的ValueState获取数据中的最大值(实际中直接使用maxBy即可)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65public class StateDemo01_KeyedState {
public static void main(String[] args) throws Exception {
//1.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);//方便观察
//2.Source
DataStreamSource<Tuple2<String, Long>> tupleDS = env.fromElements(
Tuple2.of("北京", 1L),
Tuple2.of("上海", 2L),
Tuple2.of("北京", 6L),
Tuple2.of("上海", 8L),
Tuple2.of("北京", 3L),
Tuple2.of("上海", 4L)
);
//3.Transformation
//使用KeyState中的ValueState获取流数据中的最大值(实际中直接使用maxBy即可)
//实现方式1:直接使用maxBy--开发中使用该方式即可
//min只会求出最小的那个字段,其他的字段不管
//minBy会求出最小的那个字段和对应的其他的字段
//max只会求出最大的那个字段,其他的字段不管
//maxBy会求出最大的那个字段和对应的其他的字段
SingleOutputStreamOperator<Tuple2<String, Long>> result = tupleDS.keyBy(t -> t.f0)
.maxBy(1);
//实现方式2:使用KeyState中的ValueState---学习测试时使用,或者后续项目中/实际开发中遇到复杂的Flink没有实现的逻辑,才用该方式!
SingleOutputStreamOperator<Tuple3<String, Long, Long>> result2 = tupleDS.keyBy(t -> t.f0)
.map(new RichMapFunction<Tuple2<String, Long>, Tuple3<String, Long, Long>>() {
//-1.定义状态用来存储最大值
private ValueState<Long> maxValueState = null;
public void open(Configuration parameters) throws Exception {
//-2.定义状态描述符:描述状态的名称和里面的数据类型
ValueStateDescriptor descriptor = new ValueStateDescriptor("maxValueState", Long.class);
//-3.根据状态描述符初始化状态
maxValueState = getRuntimeContext().getState(descriptor);
}
public Tuple3<String, Long, Long> map(Tuple2<String, Long> value) throws Exception {
//-4.使用State,取出State中的最大值/历史最大值
Long historyMaxValue = maxValueState.value();
Long currentValue = value.f1;
if (historyMaxValue == null || currentValue > historyMaxValue) {
//5-更新状态,把当前的作为新的最大值存到状态中
maxValueState.update(currentValue);
return Tuple3.of(value.f0, currentValue, currentValue);
} else {
return Tuple3.of(value.f0, currentValue, historyMaxValue);
}
}
});
//4.Sink
//result.print();
result2.print();
//5.execute
env.execute();
}
}
Operator State
下图对 word count 示例中的FromElementsFunction类进行详解并分享如何在代码中使用 operator state:
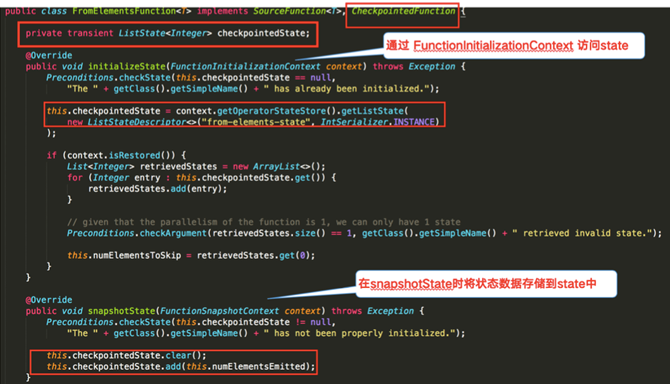
使用ListState存储offset模拟Kafka的offset维护
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84/**
* Desc
* 需求:
* 使用OperatorState支持的数据结构ListState存储offset信息, 模拟Kafka的offset维护,
* 其实就是FlinkKafkaConsumer底层对应offset的维护!
*/
public class StateDemo02_OperatorState {
public static void main(String[] args) throws Exception {
//1.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//先直接使用下面的代码设置Checkpoint时间间隔和磁盘路径以及代码遇到异常后的重启策略,下午会学
env.enableCheckpointing(1000);//每隔1s执行一次Checkpoint
env.setStateBackend(new FsStateBackend("file:///D:/ckp"));
env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
//固定延迟重启策略: 程序出现异常的时候,重启2次,每次延迟3秒钟重启,超过2次,程序退出
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(2, 3000));
//2.Source
DataStreamSource<String> sourceData = env.addSource(new MyKafkaSource());
//3.Transformation
//4.Sink
sourceData.print();
//5.execute
env.execute();
}
/**
* MyKafkaSource就是模拟的FlinkKafkaConsumer并维护offset
*/
public static class MyKafkaSource extends RichParallelSourceFunction<String> implements CheckpointedFunction {
//-1.声明一个OperatorState来记录offset
private ListState<Long> offsetState = null;
private Long offset = 0L;
private boolean flag = true;
public void initializeState(FunctionInitializationContext context) throws Exception {
//-2.创建状态描述器
ListStateDescriptor descriptor = new ListStateDescriptor("offsetState", Long.class);
//-3.根据状态描述器初始化状态
offsetState = context.getOperatorStateStore().getListState(descriptor);
}
public void run(SourceContext<String> ctx) throws Exception {
//-4.获取并使用State中的值
Iterator<Long> iterator = offsetState.get().iterator();
if (iterator.hasNext()){
offset = iterator.next();
}
while (flag){
offset += 1;
int id = getRuntimeContext().getIndexOfThisSubtask();
ctx.collect("分区:"+id+"消费到的offset位置为:" + offset);//1 2 3 4 5 6
//Thread.sleep(1000);
TimeUnit.SECONDS.sleep(2);
if(offset % 5 == 0){
System.out.println("程序遇到异常了.....");
throw new Exception("程序遇到异常了.....");
}
}
}
public void cancel() {
flag = false;
}
/**
* 下面的snapshotState方法会按照固定的时间间隔将State信息存储到Checkpoint/磁盘中,也就是在磁盘做快照!
*/
public void snapshotState(FunctionSnapshotContext context) throws Exception {
//-5.保存State到Checkpoint中
offsetState.clear();//清理内存中存储的offset到Checkpoint中
//-6.将offset存入State中
offsetState.add(offset);
}
}
}
Flink-容错机制
Checkpoint
State Vs Checkpoint
State:
- 维护/存储的是某一个Operator的运行的状态/历史值,是维护在内存中!
- 一般指一个具体的Operator的状态(operator的状态表示一些算子在运行的过程中会产生的一些历史结果,如前面的maxBy底层会维护当前的最大值,也就是会维护一个keyedOperator,这个State里面存放就是maxBy这个Operator中的最大值)
- State数据默认保存在Java的堆内存中/TaskManage节点的内存中
- State可以被记录,在失败的情况下数据还可以恢复
Checkpoint:
某一时刻,Flink中所有的Operator的当前State的全局快照,一般存在磁盘上
表示了一个Flink Job在一个特定时刻的一份全局状态快照,即包含了所有Operator的状态
可以理解为Checkpoint是把State数据定时持久化存储了
比如KafkaConsumer算子中维护的Offset状态,当任务重新恢复的时候可以从Checkpoint中获取
Checkpoint执行流程
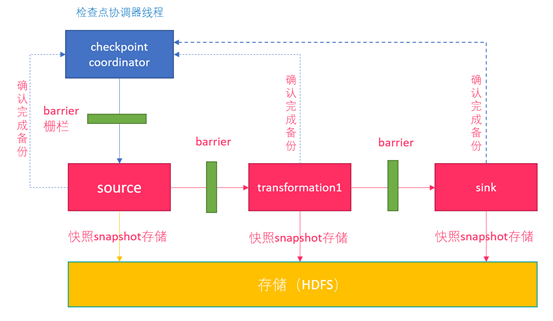
- Flink的JobManager创建CheckpointCoordinator
- Coordinator向所有的SourceOperator发送Barrier栅栏(理解为执行Checkpoint的信号)
- SourceOperator接收到Barrier之后,暂停当前的操作(暂停的时间很短,因为后续的写快照是异步的),并制作State快照, 然后将自己的快照保存到指定的介质中(如HDFS), 一切 ok之后向Coordinator汇报并将Barrier发送给下游的其他Operator
- 其他的如TransformationOperator接收到Barrier,重复第2步,最后将Barrier发送给Sink
- Sink接收到Barrier之后重复第2步
- Coordinator接收到所有的Operator的执行ok的汇报结果,认为本次快照执行成功
- 在往介质(如HDFS)中写入快照数据的时候是异步的(为了提高效率)
- 分布式快照执行时的数据一致性由Chandy-Lamport algorithm分布式快照算法保证
State状态后端/State存储介质
Checkpoint其实就是Flink中某一时刻,所有的Operator的全局快照,那么快照应该要有一个地方进行存储,而这个存储的地方叫做状态后端
MemStateBackend

FsStateBackend

FsStateBackend 构建方法是需要传一个文件路径和是否异步快照。
State 依然在 TaskManager 内存中,但不会像 MemoryStateBackend 是 5 M 的设置上限
Checkpoint 存储在外部文件系统(本地或 HDFS),打破了总大小 Jobmanager 内存的限制。
推荐使用的场景为:常规使用状态的作业、例如分钟级窗口聚合或 join、需要开启HA的作业。
如果使用HDFS,则初始化FsStateBackend时,需要传入以 “hdfs://”开头的路径(即: new FsStateBackend(“hdfs:///hacluster/checkpoint”)),
在分布式情况下,不推荐使用本地文件。因为如果某个算子在节点A上失败,在节点B上恢复,使用本地文件时,在B上无法读取节点 A上的数据,导致状态恢复失败。
RocksDBStateBackend

Checkpoint配置方式
全局配置
修改flink-conf.yaml
1 | #jobmanager(即MemoryStateBackend), |
在代码中配置
代码示例:
1 | public class CheckpointDemo01 { |
状态恢复和重启策略
自动重启策略和恢复
重启策略配置方式
全局配置:
在flink-conf.yml中可以进行配置
1
2
3restart-strategy: fixed-delay
restart-strategy.fixed-delay.attempts: 3
restart-strategy.fixed-delay.delay: 10 s在代码中配置:
1
2
3
4env.setRestartStrategy(RestartStrategies.fixedDelayRestart(
3, // 重启次数
Time.of(10, TimeUnit.SECONDS) // 延迟时间间隔
))
重启策略分类
默认重启策略
如果配置了Checkpoint,而没有配置重启策略,那么代码中出现了非致命错误时,程序会无限重启
无重启策略
Job直接失败,不会尝试进行重启
设置方式1:
restart-strategy: none设置方式2:
无重启策略也可以在程序中设置
val env = ExecutionEnvironment.getExecutionEnvironment()
env.setRestartStrategy(RestartStrategies.noRestart())
固定延迟重启策略
设置方式1:
重启策略可以配置flink-conf.yaml的下面配置参数来启用,作为默认的重启策略:
例子:
restart-strategy: fixed-delay
restart-strategy.fixed-delay.attempts: 3
restart-strategy.fixed-delay.delay: 10 s设置方式2:
也可以在程序中设置:1
2
3
4
5env = ExecutionEnvironment.getExecutionEnvironment()
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(
3, // 最多重启3次数
Time.of(10, TimeUnit.SECONDS) // 重启时间间隔
))上面的设置表示:如果job失败,重启3次, 每次间隔10
失败率重启策略
设置方式1:
失败率重启策略可以在flink-conf.yaml中设置下面的配置参数来启用:
例子:
restart-strategy:failure-rate
restart-strategy.failure-rate.max-failures-per-interval: 3
restart-strategy.failure-rate.failure-rate-interval: 5 min
restart-strategy.failure-rate.delay: 10 s设置方式2:
失败率重启策略也可以在程序中设置:
val env = ExecutionEnvironment.getExecutionEnvironment()
env.setRestartStrategy(RestartStrategies.failureRateRestart(
3, // 每个测量时间间隔最大失败次数
Time.of(5, TimeUnit.MINUTES), //失败率测量的时间间隔
Time.of(10, TimeUnit.SECONDS) // 两次连续重启的时间间隔
))
上面的设置表示:如果5分钟内job失败不超过三次,自动重启, 每次间隔10s (如果5分钟内程序失败超过3次,则程序退出)
示例代码
1 | public class CheckpointDemo02_RestartStrategy { |
Savepoint
保存点,类似于以前玩游戏的时候,遇到难关了/遇到boss了,赶紧手动存个档,然后接着玩,如果失败了,赶紧从上次的存档中恢复,然后接着玩
在实际开发中,可能会遇到这样的情况:如要对集群进行停机维护/扩容…
那么这时候需要执行一次Savepoint也就是执行一次手动的Checkpoint/也就是手动的发一个barrier栅栏,那么这样的话,程序的所有状态都会被执行快照并保存,
当维护/扩容完毕之后,可以从上一次Savepoint的目录中进行恢复!
Savepoint VS Checkpoint
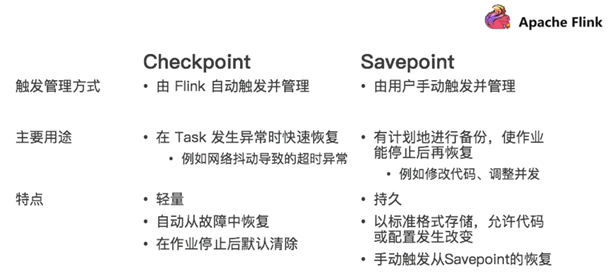

Savepoint演示
1 | # 启动yarn session |








